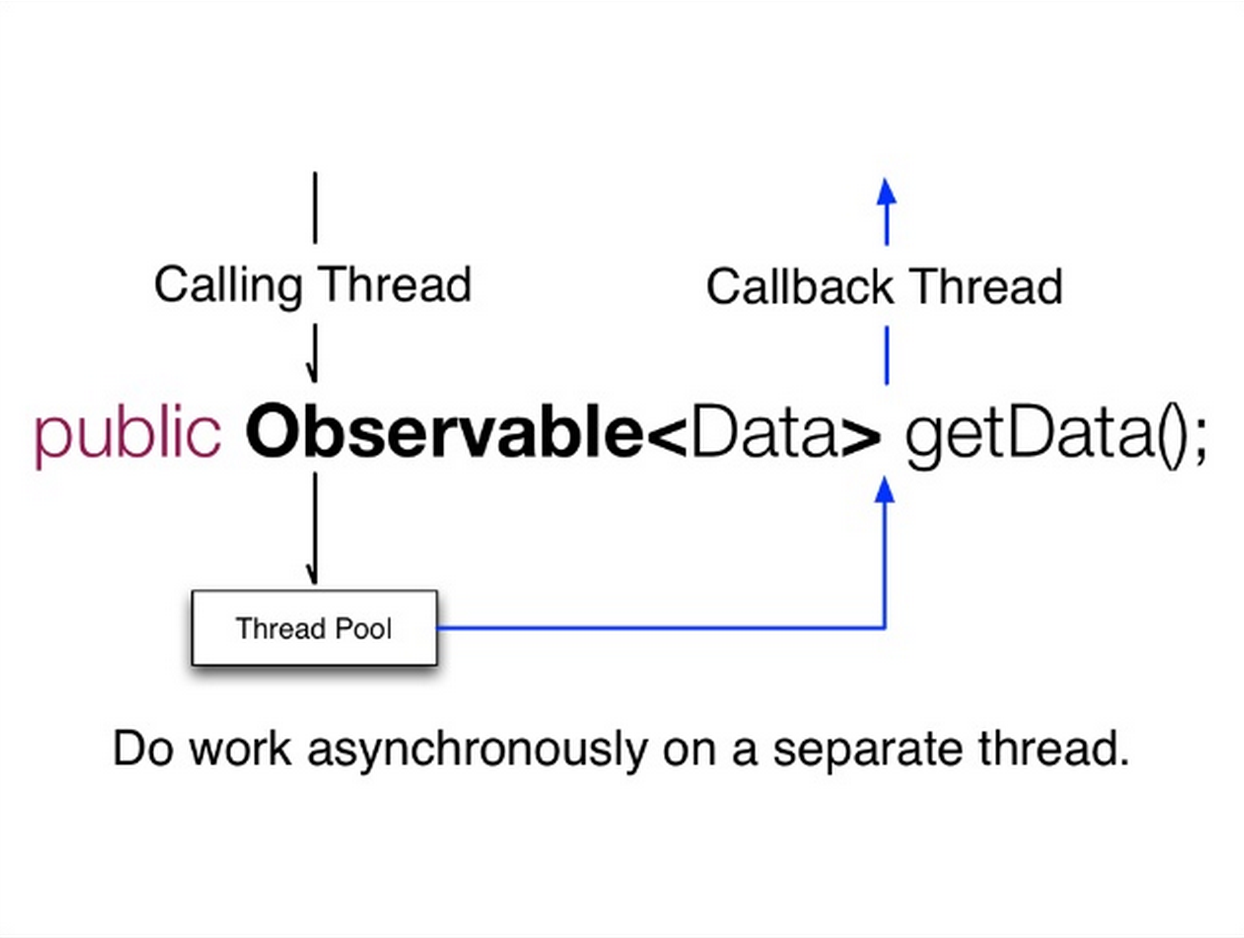
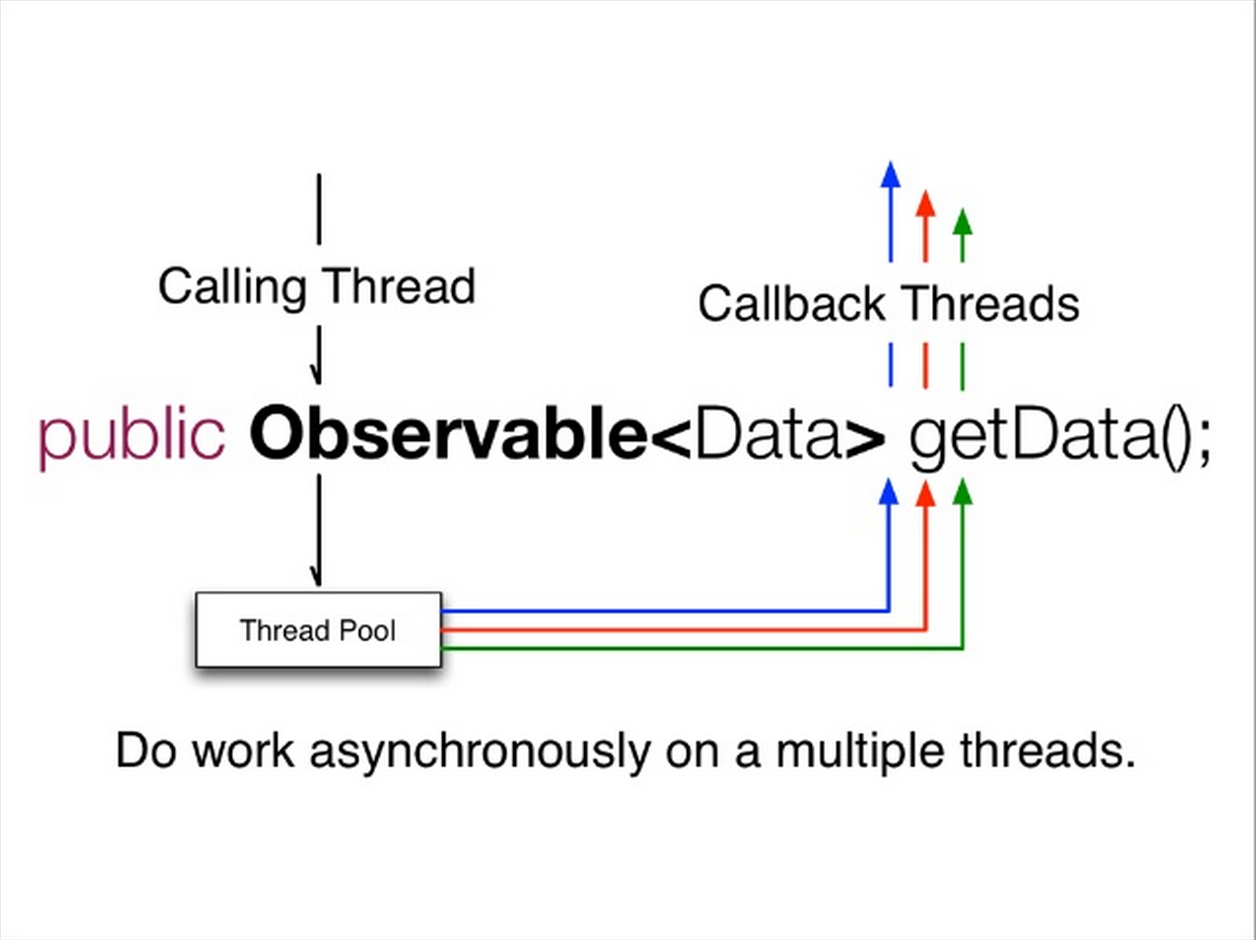
Things need to be consider when building microservice
TLDR;
IT industry never run out of buzz words, big data, SOA, Cloud, IoT, reactive.
The hostest buzz word of 2015 have to be microservice and docker.
In this posts, I’ll share my experinence of few projects I worked on over last year, which are dockerised microservice.
I won’t talk about what is microservice, why you should adopt microservice.
Outlines
To build a microservice, you’d better to think about provision and deployment at the beginning of your project.
People might get confused about provision and deployment.
In my opinon, provision is all about set up required infrastructures for your service, which including:
- Virtual Machine
- Loadbanlacner
- Reverse Proxy
- Database
- Message Queue
- Network Access Controll
- etc.
the goal of provision is a envrionment which a artifact can be deployed to.
While deployment is deploying a specific version artifact to an target environment(which has been provisioned before).
the goal of deployment is:
- a updated service up and running in health state. (deploment succeed)
- a non-updated service up and running in health state.(deploment failed)
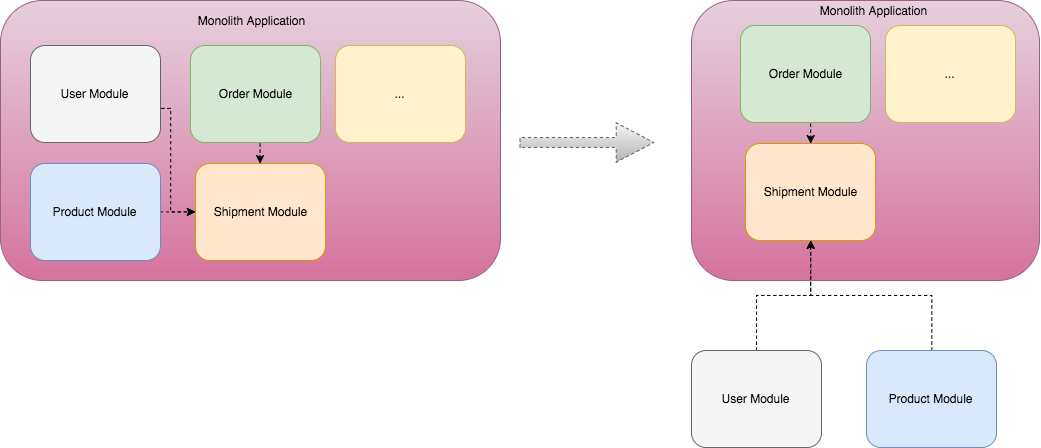
independent lifecycle is the most important feature of microservices, independent lifecycle means you need to manage your service by yourselves.
To achieve the goal of provision, you need to answer the following questions:
-
What is the target machine of your service?
a public cloud service provider(e.g. AWS, Asure) or a managed private cloud or just VMs in your own datacenter?
-
What is the network requirement?
is it a public facing service or an internal service which sits behind a firewall?
-
Is your service depends on any other infrastructrure?
e.g. a message queue, database, do you want a provsion these infrastructures by yourself, or just use a service provided by cloud service provider(e.g. RDS, SQS from AWS)?
This may affect your decision.
-
How to provision the environment?
Once you’ve chosen target environment, you need to decide how to rovision the target environment?
Options like ansible, cloudformation, chef, puppet, all of there have pros and cons, choose one fits your requirements.
As I mentioned in previous section, deployment is all about deploying a specific version artifact to an target environment.
to have your service deploy to target environment, you need to answer the following questions:
- what is the deployable artifact of your service?
- what is the automation tool of deployment?
- can I roll back to previous version if I found a critical bug in the version just deployed?
what is the deployable artifact of your service?
in a Continous Delivery(aka. CD) world, an artifact is an result of of packaging job, which is part of a CD pipeline.
artifact can be deployed to a environment and providing service.
There’re many options for artifacts, such as
- source code
- amazon machine image(aka, AMI)
- rpm/deb package
- docker image
all of them have pros and cons, I’ll give a brief overview on these options.
source code
in ruby world, there’re some tools like mina, capistrano that allow you to deploy source code into target environment.
-
The Pros:
- The advantage of this approach is that simplicity. All these tool does is provide a nicer DSL which allow you to copy source code into target machine and start them,
also, they maintained few old versions on target machine, so that you can easily roll back to an old version.
- The Cons:
-
The disadvantage of this approachs is also simplicity, if your application have any native dependencies(e.g. postgres), these tools can not help,
you have to update your provision script to ensure the target environment has required native dependencies.
-
in another word, it is hard to define a clear seperation line between provison and deployment script if you’re using tool.
- Tooling:
- mina/capistrano in ruby
- shell scripts
- Conclusion:
if you favor simplicity over maintaince, use these tools, otherwise, you should consider other options.
Amazon Machine Image
This is a quite intesresting approach, the main idea behind it is,
Given a base amazon image, spin up a EC2 instance, install your service on it as an auto started service, create a new AMI from the EC2 instance, The newly created image is artifact.
- The Pros:
- By baking your service into a machine image, spin up a new machine, roll back to a old version can be finished automaticly within few minutes.
- By baking your service and its dependence into a machine images, Consistency across difference environment can be achieved much easier.
- The Cons:
- Bakcing a new image could be time consuming.
- Make your service tightly coupled to cloud vendor’s approach. in my last projects, we’d encountered a lot of issues while Amazon start introduce a new virtual technique - HVM(hardware assisted virtual), while our projects sitll use a lot paravirtual VMs.
- Tooling:
The idea is creating a platform-specific package, which contains your service, also a manifest file which including dependence declaration.
- The Pros:
- Leverage platform’s package management capability
- The Cons:
Docker Image as artifact
The idea is baking your service into docker image and distribute it into target environment.
The time to build a ship docker images it quite fast, and start a dockerized application is even faster.
I am prepared for the worst, but hope for the best.
-Benjamin Disraeli
Bad things can happened at any time, to mitigate risks of your service, Disaster Recovery should be considered as early as possible.
Disaster includes Database Corruption, Data Center outage, etc
Each service should have their own disaster recovery strategy, but there’re some principles to follow.
in my prevous project, we as a team, come out with the follow principles.
For asynchrous backend job service:
- jobs should be idempotent, replayable
- execution metric & monitor should be used to check system healthy.
For web application
- applicaton should be stateless, which will make scale easier.
- re-creatable environment.
- automated deployment process.
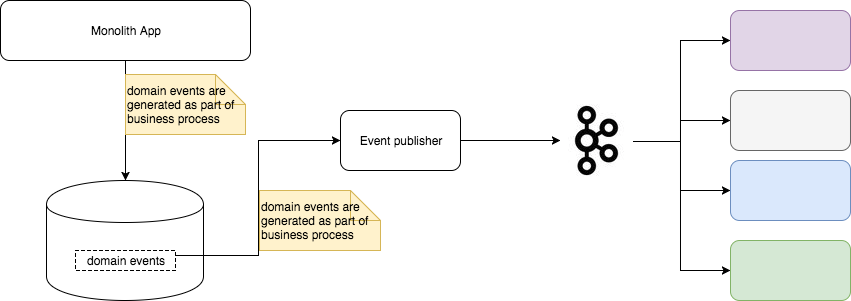
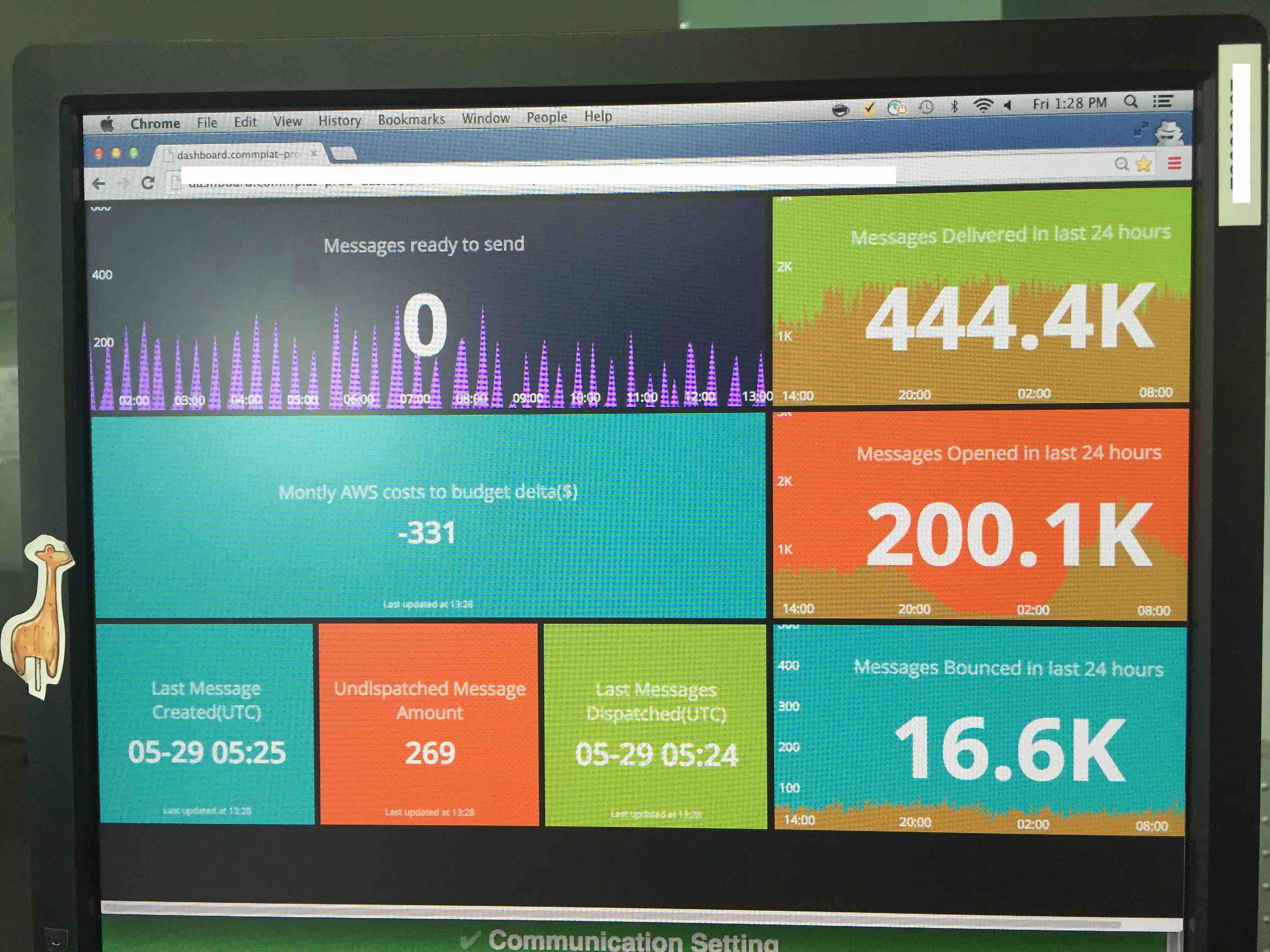
Image your company have hundreds of services in production environment, how would you trace a specific request across these systems? login to each box and grep in logs?
A comon approach is creating a central log management system. hundreds of log collection agents running along side with services on each host,
collecting logs generated by services and send back to central log management system.
Another tips is, in a large system which composed of many small services, use a generated gloabl unique transaction id across all services for each user request, this will made tracking asynchronous message much easier.
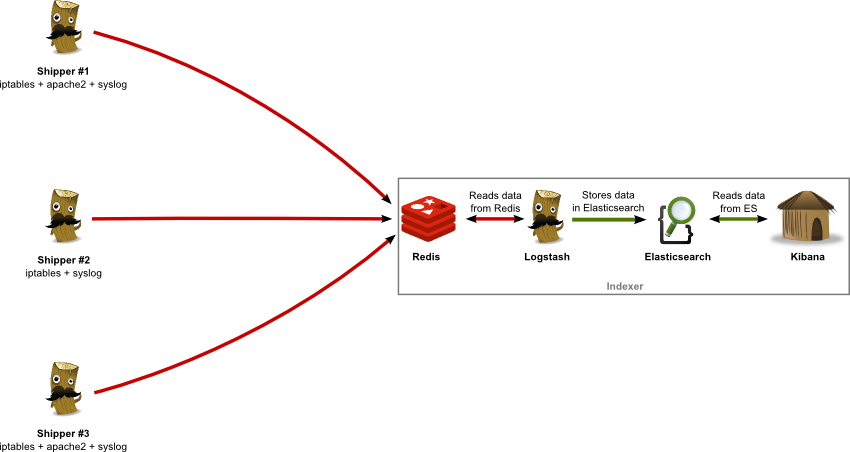
This is also a good invesment from the company’s perspective. having a central log management system, the company have a gold mine of user behaviour.
As Werner Vogels, CTO of Amazon, says: “you build it, you run it.”
microservice developers shoud have more insights of the systems they built, as it is their own responsibility to operate it.
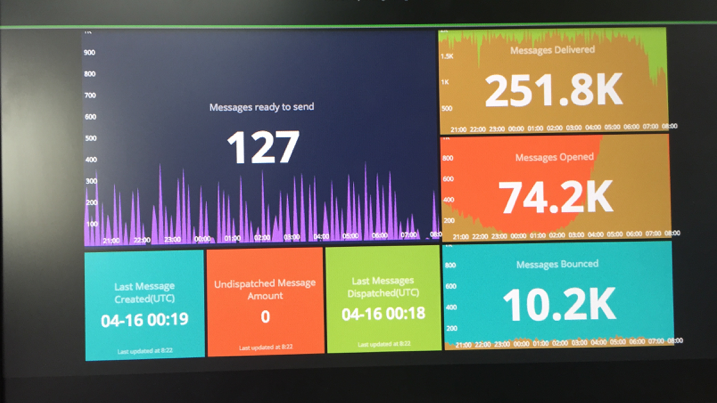
Metric
Many cloud service provider have already provided some built in metrics, e.g. CPU, Memory, Bandwidth usage. You can also create your own custom metrics.
But you’re not tied to your cloud service, there’re many 3rd-party tooling support in this area, just add a client libraray and api key in your service,
you’re able to send metrics to their server, then you’ll get a nice dashboard for your service.
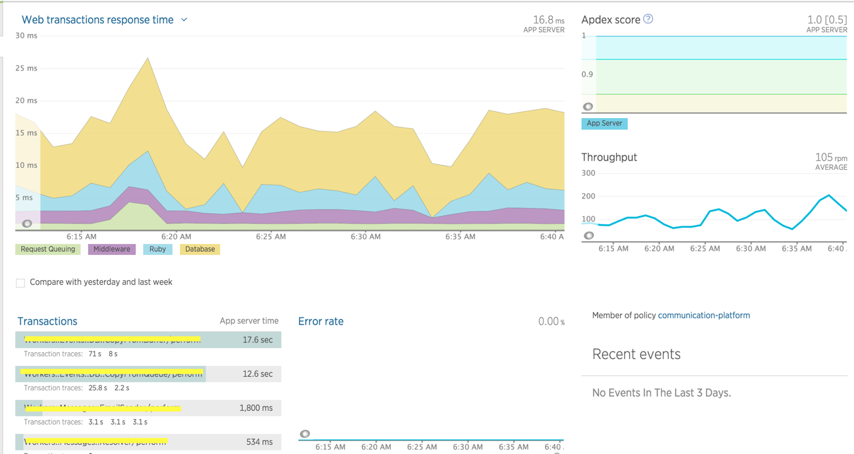
With these metrices, you can even define auto scalling policy
Alert
You want to be notified when bad things happened on your service. again, there’re many 3rd-party tooling support in this area, integrate with these service are pretty straightforward.
All you need to do is to define threshold and how you want to receive alert.
Conclusion
Again, microservice isn’t silver bullet, you need to pay significant cost to adopt microservice, be aware of these things when you start consider building your next system in a microservice style.