Lets Talk About Distributed System Architecture
分布式系统
我曾经看到过很多玩具项目,都是通过一个系统支撑所有的业务需求。 然而真正在产品环境运行的系统,一般都由多个子系统组成,各个子系统承担不同的职责,子系统之间以某种通信方式进行合作。 究其原因,不外乎单块系统架构带来的复杂性,单机系统的不可靠性。 本文笔者会将一个实际项目中系统设计部分的思考方式分享给大家。
背景介绍
我们的客户希望构建一个信息发布系统,其能够提供以下功能:
- 通过多种渠道(e.g. email/sms/mobile push notification)向他们的用户发送消息。
- 尽可能地收集用户收到这些信息后的行为。
- 基于这些行为分析用户对某类信息的接受度,以支撑后续业务决策。
模块划分
基于上面的需求,我们做的第一件事请就是划分子系统,确定系统之间的职责边界。
- api 向外暴露一组api,接受即将发送的消息并持久化起来。
- dispatcher 负责将持久化后的消息分发给一组sender,并且保证一个消息只会被dispatch一次。
- sender 负责尽可能快地将接受到的消息发送出去。
- event-collector 负责收集用户对消息的反馈。
- analyser 负责对收集到的用户行为数据进行分析并生成报表。
问题驱动
对于每个子系统,要能够正常地完成期望的工作,可以从以下几个角度考虑:
- 性能
- 可靠性
- 监控与告警
性能
对一个web系统而言,最直观的两个性能指标就是TPS(transaction per second),response time。 一个系统能否在性能上满足需求,做为架构师,我们需要能够回答下面几个问题:
- 这个系统即将面对的请求模型是什么?比如每个endpoint接受的请求占整个请求的百分比,比如可遇见的peek time(如天猫双十一)。
- 确定一个合理的期望的TPS,response time值(不要拍脑袋定,不要拍脑袋定,不要拍脑袋定,否则开发人员会被搞死的)。
- 考虑你的系统如何应对设计容量之外的请求,系统是否需要支持自动扩展?
- 如果需要,自动扩展的策略是什么?(如,响应时间大于2秒,CPU占用率大于90%并持续10分钟以上)
- 系统是否需要有流控能力(throttling & back-pressure)?例如,在上游系统消息发送过快时,告知对方降低发送速率,当没有需要处理的消息时,告知上游系统发送消息。
- 消息的时效性是什么?过了多久就可以任为这个消息是过期的?对过期消息的处理策略又是什么?
可靠性
我们最常听到人们谈到系统可靠性指标时,会提到‘两个九,三个九’,指的是系统不可用时间占比,以一年为例,99.99%的可靠性就是指一年内服务中断时间不能超过52分钟。
为了保证系统的高可靠性,我们需要考虑以下几个问题:
- 是否支持零宕机部署?即在不中断服务的情况下部署系统
- 系统是否有fail-over策略?即在某个机器宕机的情况下, 如何启动新服务继续提供服务。在我们的系统中,采用了AutoscalingGroup的能力保证提供服务的最小机器数量。
- 系统是否有fault-tolerance能力?在我们的系统中,对于一些关键数据,除了正常在数据流中流转之外,还会在S3上存放一份备份,以便在出错时还可以从备份中恢复数据。
- 系统是否有灾难恢复能力? 这是一种比较极端的场景,然而一旦出现,其带来的影响可能是毁灭性的。试想一下某个公司的服务器所在的机房突发火灾,所有资料全部丢失,那么这个公司也基本完蛋了。 我们的系统是部署在Amazon的云服务上,为了能够具备这一能力,我们创建了一些可重用的部署模板和部署脚本。那怕Amazon的某个区全部不可用,我们也有能力在另外一个区很快地把整个系统重建出来。
-
系统之间的依赖是否真得需要实时依赖? 例如,子系统A在完成某个功能时,调用系统B的某个接口并等待其返回,待结果返回后再执行后续操作,这就是实时依赖。 实时依赖有一个很大的弊端就是cascade failure - 当被依赖的系统不可用时,所有实时依赖于它的系统都变得不可用。 因此,要尽可能地避免这种实时依赖。
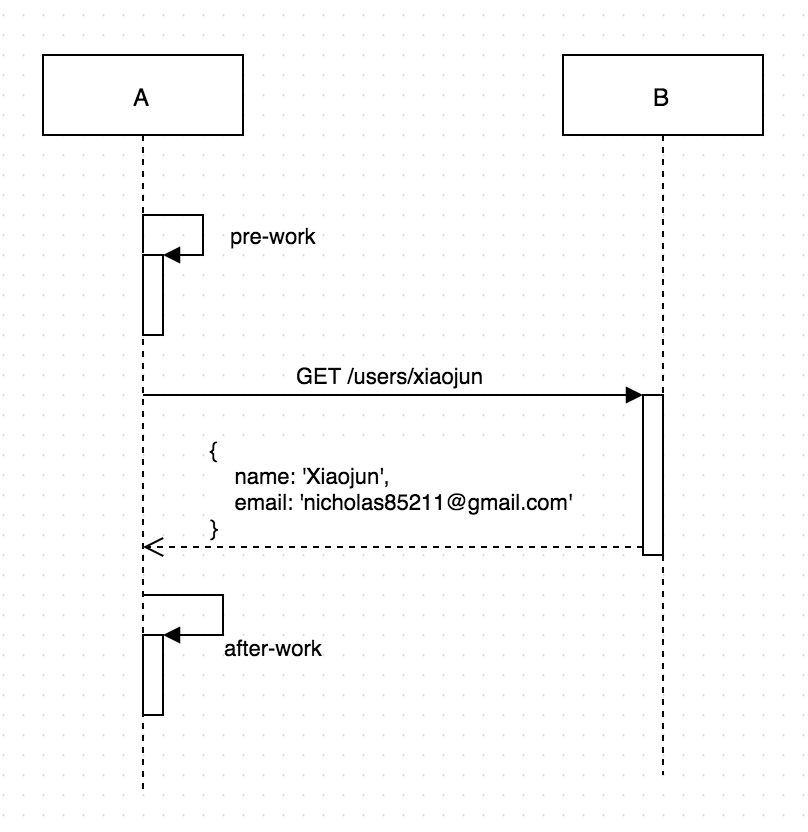
有些同事对如何避免实时依赖比较感兴趣,在这里就多说一点。假定有两个系统A和B,A系统有个功能需要从B系统获取一些信息,如果是实时依赖的实现方式,那么两个系统之间的交互方式就如下图:
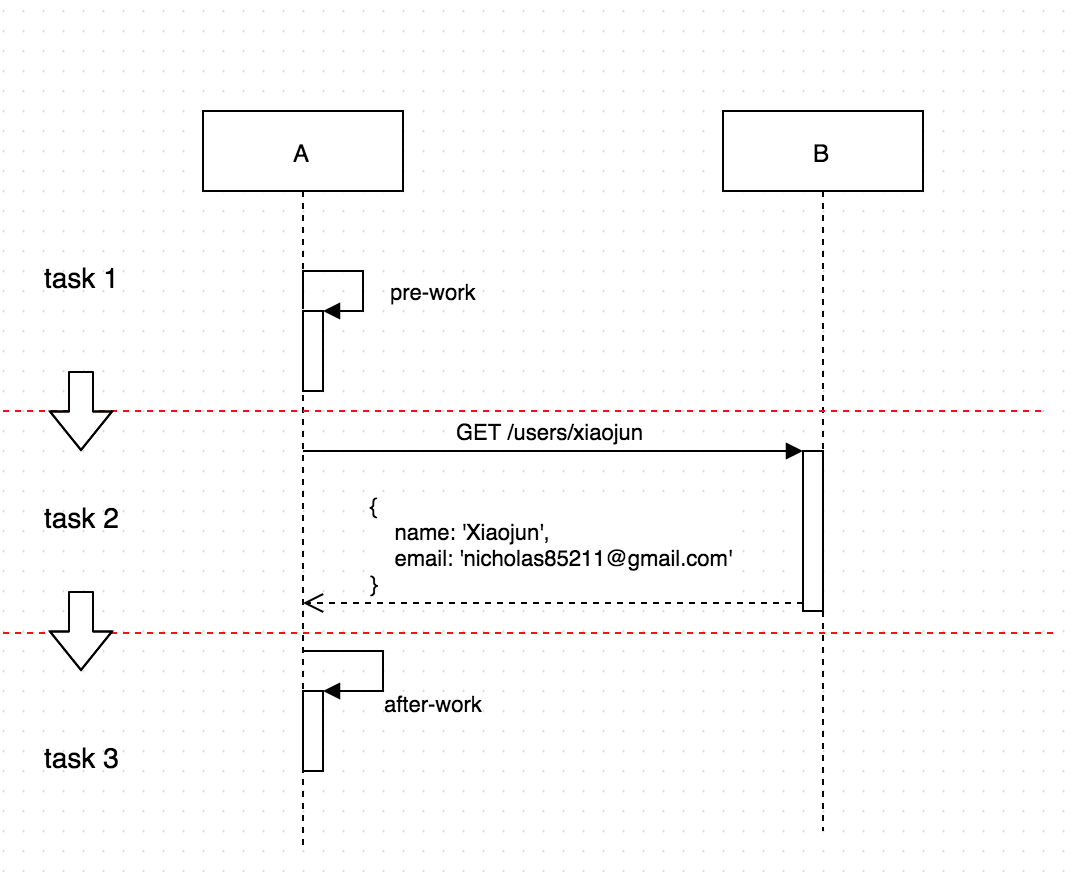
在我们的项目中采用了异步任务的方式来尽量减少实时依赖的影响,方式如下:
把pre-work,api调用,after-work划分为三个独立的任务,这些异步任务有如下特性:
- 前一个任务完成后会触发下一个任务。
- 是幂等的,即多次执行和一次执行的结果是一致的。
- 是可重试的。
异步化之后的交互方式如下图:
总结一下这个方案背后的思路:
通过把一个包含实时依赖的任务划分成多个有依赖关系的子任务,把实时依赖失败可能导致的影响限制在一个很小的范围内,并且,提供了良好的错误恢复机制,这也是design-for-failure思想的体现。
监控与告警
系统上线之后,我们可不希望直到客服找到我们的时候才执行我们的系统出现问题。 因此,在上线之前,我们需要回答下面这些问题:
- 系统的一些关键路径的性能如何,我们能时刻知道吗?
- 当系统主要功能出现问题时,系统能够主动报警吗?
我们系统里使用了不少工具来解决此类问题,这里跟大家分享一下
Newrelic
newrelic是一个SaaS的付费服务,主要提供了性能监控,报警等能力。 newrelic提供了多种语言的api,开发人员可以通过这些api监控代码中的关键路径。在系统运行时,newrelic agent会随之启动,并监控这些关键路径的执行时间,错误信息并上报给newrelic server。
Pagerduty
提供告警能力,在告警发生时,可通过电话,短信,邮件,push notification多种渠道通知运维人员。
CloudWatch
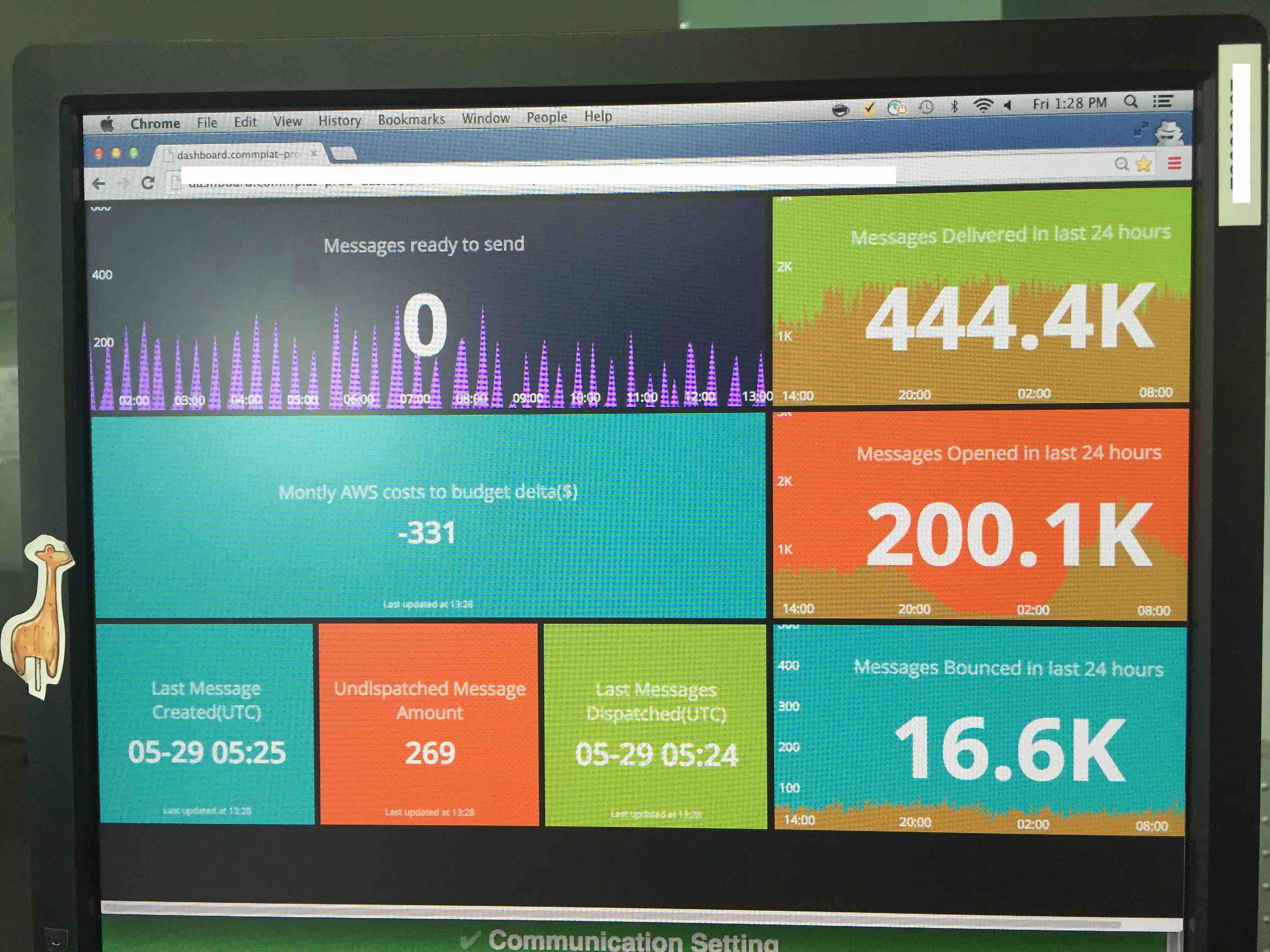
CloudWatch是Amazon提供的一种度量服务,这里我主要说下customised metric在系统关键路径收集数据并通过CloudWatch api上报,Amazon会存储这些数据并通过API暴露出来,开发人员可以选择用合适的方式将其可视化出来。
我们系统的dashboad就是把这些度量数据展示出来。
Splunk
splunk主要有两种角色:splunk-forwarder和splunk-indexer 在每个子系统上运行一个splunk-forwarder,收集指定的日志文件并转发给splunk-indexer。 splunk-indexer提供日志的索引,搜索能力。