RxJava初探
RxJava 是来自于Netflix的Reactive Extension的java版实现。
Reactive Extenstion所要解决的一个问题是对多个异步任务的组合,依赖所带来的编码复杂性的问题,我们先从一个例子看起:
异步任务的依赖
假设我们的程序需要从五个micro-service获取数据,这些micro-services之间存在依赖关系,我们来看一下第一版实现:
note: 本文我使用了scala来做为RxJava的客户端代码,只是因为scala中支持lambda。关于rx-scala的更新信息,参阅这里
val fa = callToRemoteServiceA();
val fb = callToRemoteServiceB();
val fc = callToRemoteServiceC(fa.get());
val fd = callToRemoteServiceD(fb.get());
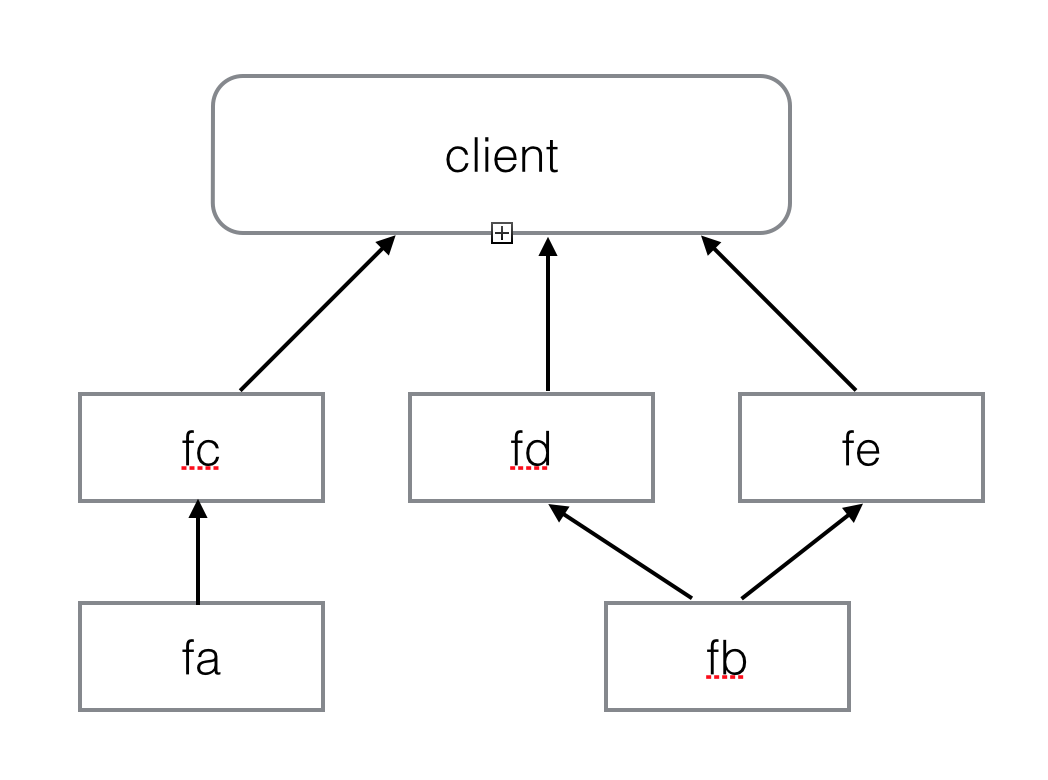
val fe = callToRemoteServiceE(fb.get());fa, fb, fc, fd, fe之间的依赖关系如下:
 </img>
</img>
由于这些future之前有依赖关系(fa,fb的执行结果是fc,fd,fe的输入),我们必须调用fa.get(), fb.get(), 而这会阻塞主线程的执行。
那么这种阻塞能否避免呢?当然可以,我们可以分别新起一个线程来创建fc, fd, fe。来看第二版实现:
val fa = callToRemoteServiceA();
val fb = callToRemoteServiceB();
val fc = executor.submit(new Callable[String]() {
override def call(): String = callToRemoteServiceC(fa.get).get
})
val fd = executor.submit(new Callable[String]() {
override def call(): String = callToRemoteServiceD(fb.get).get
})
val fe = executor.submit(new Callable[String]() {
override def call(): String = callToRemoteServiceE(fb.get).get
})在这个实现里,我们分别启动了一个线程来等待fa,fb的执行结果,然后再执行fc, fd, fe, 这样,主线程就不会被阻塞,然而,这却大大地增加代码的复杂度。
那么,能否不要等待future的执行结果(poll),而是等到Future执行完成的时候被通知到(push),Reactive Extenstion的Observable的出现就解决了这样的问题,我们先来看一下实现:
val oa = from(callToRemoteServiceA)
val ob = from(callToRemoteServiceB())
val oc = oa.flatMap { res => from(callToRemoteServiceC(res)) }
val od = ob.flatMap { res => from(callToRemoteServiceD(res))}
val oe = ob.flatMap { res => from(callToRemoteServiceE(res))}在这个版本的实现中,对ServiceA和ServiceB的调用被包装为一个Observable对象, 然后使用flatMap来把micro services 之间的依赖串接起来:
对ServiceC的调用依赖于对ServiceA的调用,因此,我们在oa上调用flatMap方法, flatMap接受一个函数,参数为Observiable的每个元素,返回值为一个新的Observable。 这里我们传入的是:
res => from(callToRemoteServiceC(res))就是对于oa的每个元素,用其做为参数调用ServiceC,并且包装成一个Observable。对ServiceD, ServiceE的调用也是类似的。
这个方案与上面方案最大的不同是,上面的例子中,我们需要不断地询问对ServiceA的调用是否完成, 若调用完成,再进行下面的动作(发起对ServiceC的调用)。
即便启动了新的线程以便不block在主线程,这个新的线程还是会被block住。
而在这个方案中,我们只需要定义好对ServiceA的调用完成后,需要做那些事情(发起对ServiceC的调用),代码也简洁了很多。
如果有个ServiceF依赖于ServiceE的执行结果,我们也可以很容易地通过flatMap来表述他们的依赖关系:
val of = oe.flatMap { res => from(callToRemoteServiceF(res)) }Reactive Extension中的概念
Observable
__Observable__用于表示一个可被消费的数据集合(data provider),它后面的数据的产生机制或者是同步的,或者是异步的,这都不重要的,最重要是它提供了下面的能力:
-
Observei可以通过Observable的subscribe向其注册。
-
当Observable中有数据产生时,调用Observer的onNext方法通知有新数据到来。
-
当Observable数据发送完毕时,调用Observer的onComplete方法通知数据发送完毕。
-
当Observable内部出现错误时,调用Observer的onError方法通知有错误需要处理。
Observable 之于 Iterable
Observable 做为一个数据(事件)集合的抽象,也支持类似于Iterable上的各种,转换、组合操作,如map,filter,merge等等,我们还是先从一个例子来看:
假设有一个GUI应用,我们使用一个Observable actions 来表示用户在界面上的操作(可能的值有click, drag, drop),
//这里我用interval模拟这些操作是异步的
val actionList = List("click", "drag", "drop", "click", "click")
val actions = interval(1 seconds).map(_.toInt).take(5).map(actionList(_))有一个收集用户点击事件并打印日志的需求,我们该怎么实现呢?
actions.filter(_ == "click").subscribe(println("clicked at " + new Date()))是不是和Iterable的操作非常相像? 实际上Observable和Iterable在很多方面都很相似:
- 都是数据的容器。
- 都可以对其应用一个映射函数(map, flatMap),从而得到一个新的Iterable/Observable。
- 都可以对其中中的元素进行过滤,从而得到一个元素数量更少的Iterable/Observable。
Observable和Iterable最大的不同点:
Observable对其消费者push数据,而Iterable没有这种能力。
Iterable的消费值只能通过`pull`的方式获取数据。
而这种`push`的能力在Reactive Programming世界中极其重要。
Observer 之于 Observer Pattern
__Observer__的概念来自于设计模式中的Observer模式,并对其行为进行了扩展。设计模式中的Observer模式定义如下:
有一个subject对象,它维护一个observer对象列表,当它的状态发生变化时,它会逐个通知这些observer。
这里的Observer只有对外暴露一个行为:update, 当subject的状态发生变化时,
subject通过这个update接口通知observer。
RxJava中的Obsever的这个update接口叫做onNext, 同时在此基础之上添加了两个行为:onCompleted和onError,以应对Observable的这种特殊的data providersubject的需求:
- onCompleted, 当Observable数据发送完毕后,调用此接口通知Observer。
- onError,当Observable产生数据过程中出现错误时,调用此借口通知Observer。
总结
最后,引用RxJava中对Observable的解释:Observable填补了在异步编程领域中访问包含多个元素的异步序列的空白, 他们的关系正如下表所示:
| single item | multiple items | |
|---|---|---|
| synchronous | T getData() |
Iterable<T> getData() |
| asynchronous | Future<T> getData() |
Observable<T> getData() |
RxJava极大地改进了java异步编程的体验,如果你受够了block Future,以及弱爆了容错机制,体验一下rxjava吧。
上面的示例代码在这里都可以找到。
更多资料,参考RxJava的wiki, 我只能帮到你这儿了 :)
 上述步骤也体现了ajax如何在javascript单线程执行模型下工作的,关于javascript单线程执行的细节,
我的前同事四火最近写了一篇关于
上述步骤也体现了ajax如何在javascript单线程执行模型下工作的,关于javascript单线程执行的细节,
我的前同事四火最近写了一篇关于