Get Data Out Of Monolith In Real Time
Exposing event stream from monolith
背景
随着微服务概念的流行,微服务得到到越来越多的企业的青睐,开发团队开始构建自己的微服务,笔者了解到的企业的微服务之路大致如下:
始于单体架构(Monolith)
大多巨型应用一开始都是从一个很小的应用逐渐成长起来的,随着业务的增长,更多的功能被加入进来,几年下来,这个应用可能已经变成了庞大的代码库,单块架构的缺点已经严重拖累了团队的效率。
拥抱微服务(Mirocservices)
基于以上的问题,团队开始了解微服务实践,然而,拥抱微服务不可能一蹴而就,一个常见的方法就是分而治之:
-
当一个新需求需要改动Monolith中的一个模块时,构建一个新的微服务,集成到Monolith。
-
重复此步骤直至所有Monolith中的模块都被拆分到各个新的微服务中。
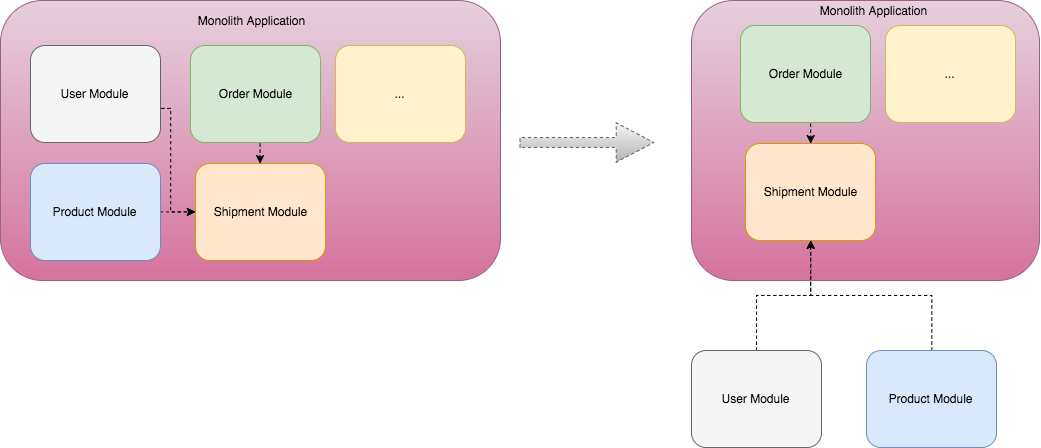
微服务的问题
在上面的过程中,首先要解决的问题就是如何把微服务与现有Monolith系统的耦合。
在大多数情况,微服务都需要与Monolith中的各个模块交换数据来实现业务流程,一种最常见的方式是在Monolith中增加REST api,微服务通过同步调用这些REST api与Monolith集成,然而这也意味着这个微服务的交付周期与Monolith耦合起来了,而与Monothlith的交付周期解耦合本是创建微服务的一大驱动力。
因此,把微服务与Monolith应用的的同步依赖解耦就成为了最关键的步骤。
本文将通过这个实际案例讲述通过Streaming platform解耦微服务之间的同步依赖,在此过程中遇到的问题以及解决方案。
架构
笔者现在服务的公司的主要业务是面向建筑行业提供项目协作平台,其中核心的Monolith应用已经有20多年的历史,在过去几年时间里,我们围绕这个Monolith创建了大约十几个微服务,每个微服务都需要通过REST api与Monolith应用进行协作。
然而这种Monolith与微服务之间的同步依赖也存在着其他问题,整个系统的扩展性并没有得到提升,微服务所承担的系统压力仍然会被传递到Monolith上,我们选择的方式,移除同步依赖。
我们把Monolith应用的数据以Event的形式发布到Kafka topic上, 微服务订阅这个topic获取历史数据和实时数据,在本地数据库中构建适合自身业务场景的projection,以前需要同步调用Monolith应用API的地方,都可以被替换为使用本地的projection,这样就消除了同步调用依赖。
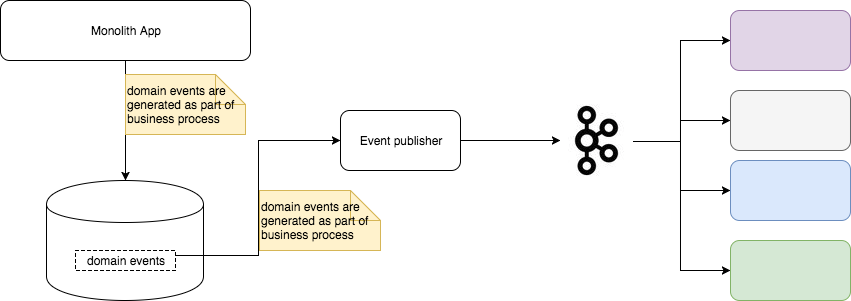
如图所示,把Monolith应用数据发布为event stream需要以下几个步骤:
- 对Monolith应用中的业务流程进行建模,得到一组表述业务事件的数据模型
- 在各个业务流程中植入生成业务事件的代码
- 生成业务事件每个事件被分配一个唯一的,线性增长的序列号(参考数据库中的sequence)
- 作为在业务流程Transaction的一部分,持久化到
domain_events表中
Source connector负责:- 监视
domain_events表中的数据,一旦有新数据产生就读取,发布到Kafka集群中。 - 维护当前已经发布的数据的序列号,并及时持久化序列号,尽量减少重复发布的数据。
- 监视
Event是如何生成的?
从上图可以看出,前两步把Monolith系统中数据的变化以event的形式持久化下来,做为其他系统的输入,这个其实跟数据库领域中CDC的概念非常相似,不同的是,这里我们对捕捉领域模型的变化,而CDC是捕捉对数据库表的变化。Confluent开源了一个Postgres的CDC实现。
Event是如何发布的?
Kafka社区已经有了很多的Kafka connector,(包括Source Connector和Sink Connector)。笔者强烈建议首先在这里寻找适合项目场景的connector, 如果找不到合适的,再去尝试实现自己的connector。
在笔者的项目里,Monolith使用的是Microsoft SQLServer, 数据库表的设计并不能很好的与现有的领域模型对应,上述的任何Source Connector都难以胜任这种场景,于是我们团队自己实现了一个 bridge 组件用于把事件数据从ms sqlserver中发送到kafka集群中。
Event是如何被消费的?
在实现event stream的消费者时,我们使用了Kafka Stream,这个库提供event stream的抽象,开发者无需关心offset管理这种底层逻辑。
值得一提的是,由于一个消息可能会出现在event stream的多个位置(kafka的at-least-once),消费者的实现必须是幂等的(idempotent)。
挑战
在实施上述架构的过程中,我们遇到了以下挑战:
数据的高可靠性 (dualbilty)
笔者所在的项目,任何数据的丢失意味着event stream上的数据与源数据永久地不一致,这对event stream的消费者来说是不可接受的。
为了保证发布到Kafka集群上的数据不会丢失,在N个broker的kafka集群中, 关于log replication的配置如下:
default.replication.factor = N #同步replica的数量 + 异步replica的数量
min.insync.replicas = N-1 #同步replica的数量
此配置的目的在保证数据一致性的前提下,Kafka集群在失去ceil(N-1/2)个节点后仍然能够接受数据读写操作。
数据的顺序保证 (order guarentee)
Kafka仅在单个partition内保证顺序,因此,挑选一个合适的partition key 极为关键。
数据的低冗余 (low duplication)
在实现bridge时,及时计算已发送成功(Kafka broker发回了成功回执)消息的最小序列号极为关键,当bridge因为某种原因停止工作,重新启动bridge后,个最小序列号就是bridge失败重试的起点。
我们通过以下手段减少数据冗余:
- 限制
in-flight(正在向Kafka broker发送并且等待回执)的message数量 - 及时计算被已发送成功的消息的最小序列号并保存到持久化设备。
为什么用Kafka?
业务事件被保存到domain_events表之后,就需要发布到event stream了, 在选择event stream的载体时,数据的高可靠性,顺序保证,系统的可伸缩性被做为重要的衡量标准。
可靠性
Kafka采用了log based storage, 发送到broker的数据被添加在日志文件的尾部,由于避免了数据存储中昂贵的”查询修改“操作,使得其有及高的存储性能。
并且Kafka的replication保证了所有保存到Kafka Broker数据日志的数据都会有多个备份,从而降低了数据丢失的概率。
顺序保证
Kafka的数据日志支持数据切片(partition),在同一个partition内部,数据被存储的数码就是broker收到该数据的顺序,因此,选择合适 的partition key可以保证在数据的顺序。
可伸缩性
Kafka broker集群支持增加或者减少节点,我们可以根据系统容量调节集群的节点数量,Kafka可以自动地把partition在broker节点之间重新分配
对流处理平台的友好性
Confluent的Streaming data platform中介绍了Kafka作为系统间数据集成的应用场景:
The streaming platform captures streams of events or data changes and
feeds these to other data systems such as relational databases,
key-value stores, Hadoop, or the data warehouse.
This is a streaming version of existing data movement technologies such as ETL systems.
而Kafka把过去和未来的数据统一在同一种api Stream<Key, Message>下,从而使得使用Kafka做流处理变得非常自然。
消息的持久性
在笔者的项目中,Kafka topic中的消息的有效期是Integer.MAX_VALUE小时(约等于245146年),event stream的消费者可以自由的设置其起始位置,处理event stream上的所有数据。
总结
Monolith持续不断地把业务事件发布到Kafka承载的event stream上, 微服务通过订阅event stream,在本地构建应用所需要的projection,再与应用自己的数据库聚合对外提供服务,
这样,我们就消灭了微服务与Monolith之间的同步依赖,转而通过event stream在微服务与Monolith传递数据,更进一步,微服务与微服务之间数据传输也可以通过Kafka承载的event stream实现。