Terraform Tips: Multiple Environments
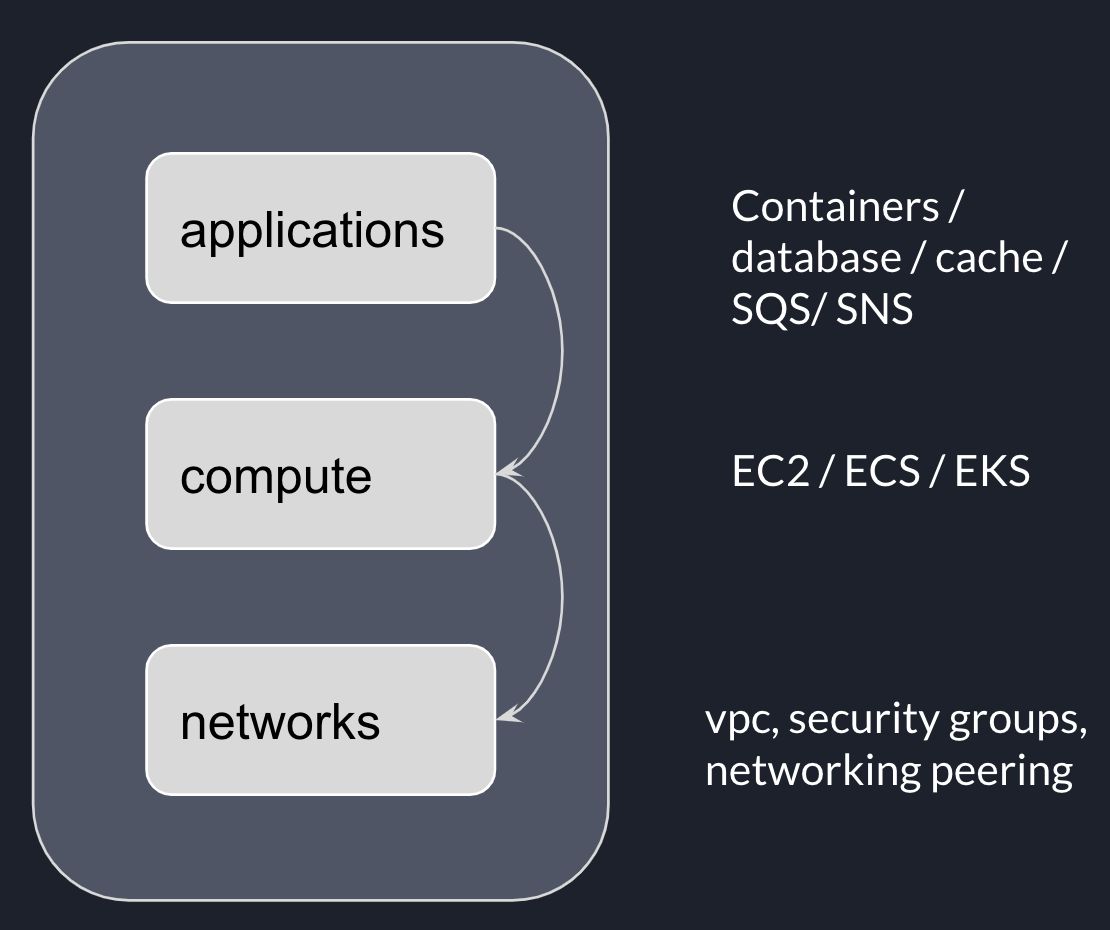
In last post, we explored the idea of layered infrastructure and the problem it was trying to solve.
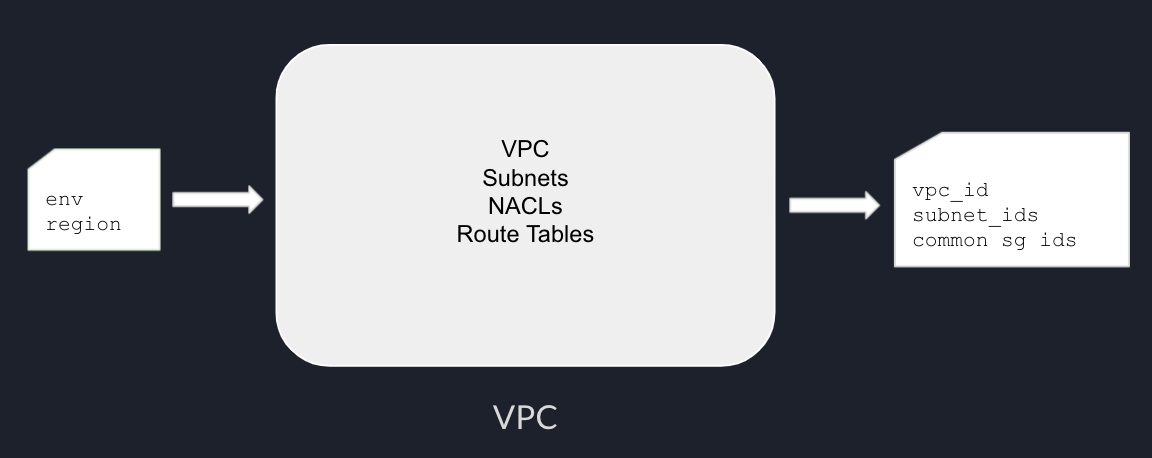
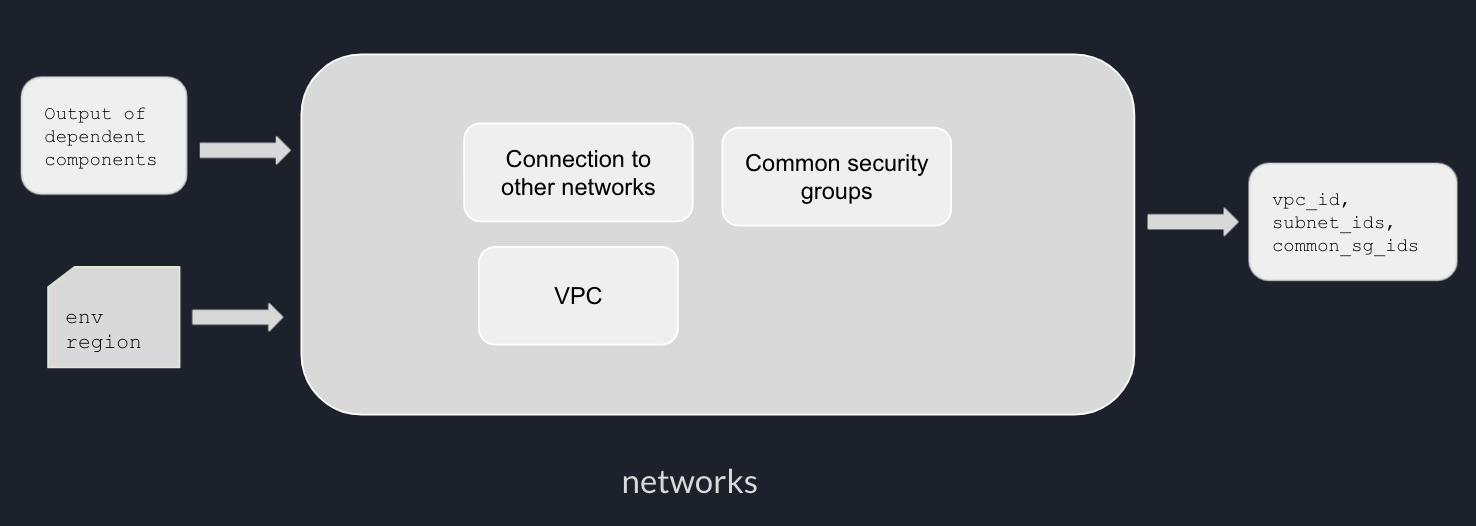
One of the benefits of using Terraform to provision multiple environments is consistency. We can extract environment-specific configurations such as CIDR, instance size, as Terraform modules variables, and create a separate variable file for each environment.
In this post, we will talk about different options to provision multiple environments with terraform.
In a real-life infrastructure project, remote state store and state locking are widely adopted for ease of collaboration.
One backend, many terraform workspaces
I have seen some teams using terraform workspace to manage multiple environments. Many backends support workspace.
Let’s have a look at an example using S3 as the backend.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.35.0"
}
}
backend "s3" {
bucket = "my-app"
key = "00-network"
region = "ap-southeast-2"
encrypt = "true"
lock_table = "my-app"
}
}
It is pretty straightforward to create multiple workspaces and switch into each workspace.
terraform workspace new dev
terraform workspace new test
terraform workspace new staging
terraform workspace new prod
terraform workspace select <workspace-name>
Each workspace’s states will be stored under a separate subfolder in the S3 bucket.
e.g.
s3://my-app/dev/00-network
s3://my-app/test/00-network
s3://my-app/staging/00-network
However, the downside is that both non-prod and prod environments’ states are stored in the same bucket. This makes it challenging to impose different levels of access control for prod and non-prod conditions.
If you stay in this industry long enough, you must have heard stories of serious consequences of “putting all eggs in one basket.”
One backend per environment
If using one backend for all environments is risky, how about configuring one backend per environment?
parameterise backend config
One way to configure individual backend for each environment is to parameterize backend config block. Let’s have a look at the backup configure of the following project structure:
├ components
│ ├ 01-networks
│ ├ terraform.tf # backend and providers config
│ ├ main.tf
│ ├ variables.tf
│ └ outputs.tf
│
│ ├ 02-computing
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.35.0"
}
}
backend "s3" {
bucket = "my-app-${env}"
key = "00-network"
region = "ap-southeast-2"
encrypt = "true"
lock_table = "my-app-${env}"
}
}
Everything seems OK. However, when you run terraform init in the component, the following error tells the brutal truth.
Initializing the backend...
╷
│ Error: Variables not allowed
│
│ on terraform.tf line 10, in terraform:
│ 10: bucket = "my-app-${env}"
│
│ Variables may not be used here.
╵
It turns out there is an open issue about supporting variables in terraform backend config block.
passing backend configure in CLI
terraform init supports partial configuration
which allows passing dynamic or sensitive configurations.
This seems a perfect solution for dynamically passing bucket names based on environment names.
We can create a wrapper script go for terraform init/plan/apply, which create backend
config dynamically based on environment and pass as additional CLI argument.
Then we can structure our project as follows.
├ components
│ ├ 01-networks
│ │ ├ terraform.tf # backend and providers config
│ │ ├ main.tf
│ │ ├ variables.tf
│ │ ├ outputs.tf
│ │ └ go
│ │
│ ├ 02-computing
│ │ ├ terraform.tf
│ │ ├ main.tf
│ │ ├ variables.tf
│ │ ├ outputs.tf
│ │ └ go
│ ├ 03-my-service
│ │ ├ ....
│
├ envs
│ ├ dev.tfvars
│ ├ test.tfvars
│ ├ staging.tfvars
│ └ prod.tfvars
Let’s take a closer look at the go script.
# go
_ACTION=$1
_ENV_NAME=$2
function init() {
bucket="my-app-${_ENV_NAME}"
key="01-networks/terraform.tfstate"
dynamodb_table="my-app-${_ENV_NAME}"
echo "+----------------------------------------------------------------------------------+"
printf "| %-80s |\n" "Initialising Terraform with backend configuration:"
printf "| %-80s |\n" " Bucket: $bucket"
printf "| %-80s |\n" " key: $key"
printf "| %-80s |\n" " Dynamodb_table: $dynamodb_table"
echo "+----------------------------------------------------------------------------------+"
terraform init \
-backend=true \
--backend-config "bucket=$bucket" \
--backend-config "key=$key" \
--backend-config "region=ap-southeast-2" \
--backend-config "dynamodb_table=$dynamodb_table" \
--backend-config "encrypt=true"
}
function plan() {
init
terraform plan -out plan.out --var-file=$PROJECT_ROOT/envs/$_ENV_NAME.tfvars #use env specific var file
}
function plan() {
init
terraform apply plan.out
}
Then, we can run ./go plan <env> and ./go apply <env> to provision components for each environment with separate
backed config.