Terraform Tips: Layered Infrastructure
Terraform Tips: Layered Infrastrucutre
Terraform have been a significant player in the infrastructure as code field. Since its first release in 2014, it has been widely used in the industry. Terraform finally reached 1.0 on 8 June 2021.
It is dead simple to provision and manages resources via terraform’s human-readable, declarative configuration language. However, you might only see the challenges when using it with anger in real-life projects. In this post, we’ll talk about the idea behind layered infrastructure; The problem it was trying to solve, and how to adapt it in your project.
Technically, we can provision a whole environment including networks, subnets, security groups, data stores, EC2 instances in one single terraform file. See the example below.
└── infra
├── prod
│ └── main.tf
├── qa
│ └── main.tf
├── dev
│ └── main.tf
└── stage
└── main.tf
However, this would lead to a slow deployment process.
To apply any resources changes, terraform would have to query and compare the state for each resource defined in main.tf.
We knew that the frequency of changes to different types of resources varies drastically; for example, the chance of changing the number of EC2 instances would be significantly higher than VPC CIDR. It would be a massive waste for terraform to compare hundreds of nearly unchanged resources to increase the instance number for an AutosScalingGroup.
If we use a remote state store, we can only apply any infrastructure changes to the environment one at a time.
There’s room for improvement. In a standard application deployment, we can classify these resources into layers such as application, compute and networks; the higher layer can depend on resources in lower layers.
Resources such as docker containers, data store, SNS topics, SQS queue, Lambda function are usually owned by an application.
Resources such as EC2 instances, ECS or EKS clusters, providing computing capabilities, are usually shared across different applications.
Resources such as VPC, subnets, internet gateway, Network Address Translation (NAT) Gateway, network peering are essential to provision resources mentioned above. With these layered infrastructures, we can provision resources in different layers independently.
This is the idea of “layered infrastructure”, here is a layout of the project adopting layered infrastructure.
├ components # components for an environment
│ ├ 00-iam # bootstrap roles which will be used in higher layers
│ ├ 01-networks
│ ├ 02-computing
│ ├ 03-application
├ modules # in-house terraform modules
As you can see from the layout, prepending number to component name makes it easy to understand their dependency.
Now let’s have a closer look at this layout. The layered infrastructure has three key concepts, module, component and environment.
Module
A Terraform module is a set of Terraform configuration files in a single directory intended to organise, encapsulate, and reuse configuration files, providing consistency and ensuring best practices. A terraform module usually has the following structure:
.
├── LICENSE
├── README.md
├── main.tf
├── variables.tf
└── outputs.tf
For example, terraform-aws-vpc is a community module that can be used to provision VPC with subnets.
You can also maintain in-house terraform modules for shared codes within your organisation.
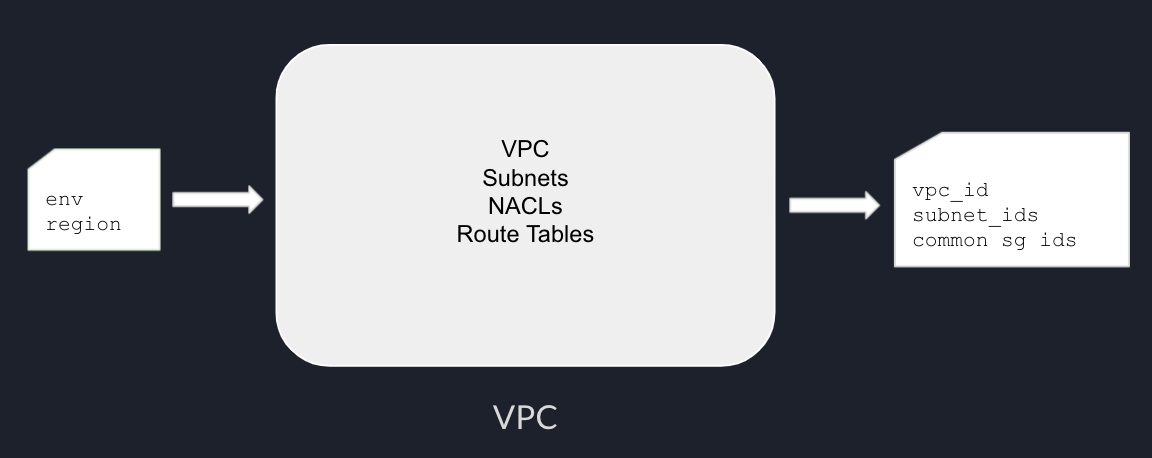
Component
An environment components groups multiple closely related modules or resources together. It can be provisioned independently within an environment. A component might depend on other components; Cyclic dependency must be avoided in component dependencies. A component usually has the following structure:
.
├── terraform.tf // backend configuration
├── provider.tf
├── main.tf
├── variables.tf
├── outputs.tf
└── go // entry point for `terraform plan`, `terraform apply` and `terraform destroy`
Example of network components.
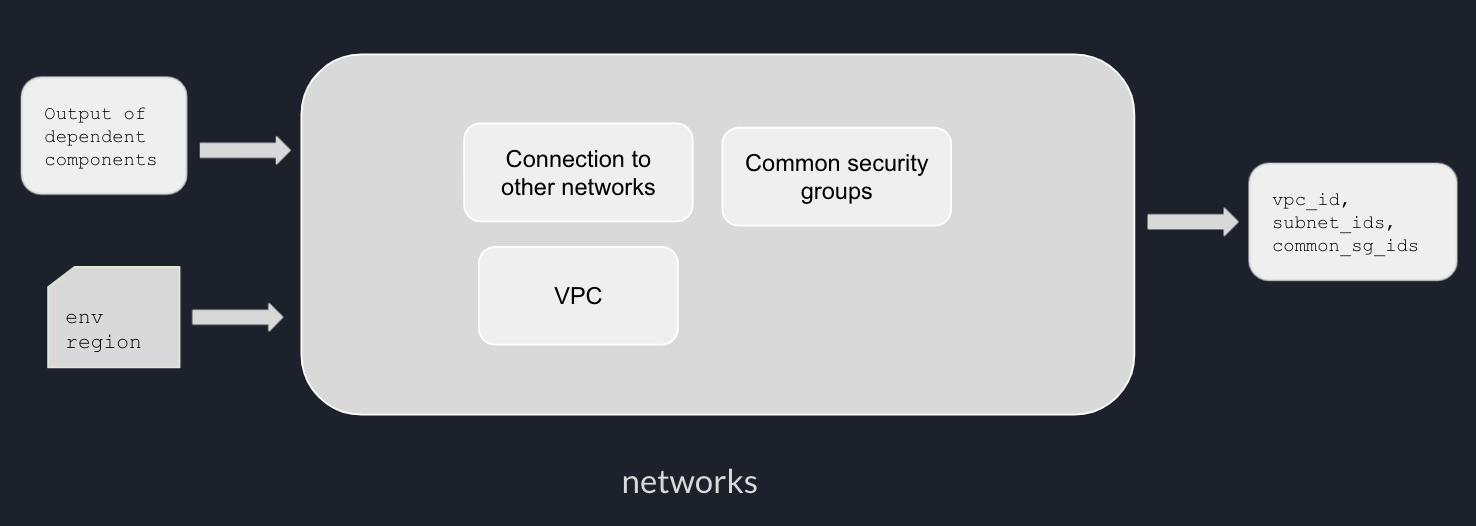
Environment
In the context of infrastructure as code, an environment is an isolated deployed instance of one or more components configured for a specific purpose, e.g. “dev”, “test”, “staging”, “production”.
All environments should have the same layout, with knot can be adjusted according to each environment.
The only difference between environments should be captured in an environment-specific file tfvar.
Let’s revisit the example project layout for an environment.
├ components # components for an environment
│ ├ 00-iam # bootstrap roles which will be used in higher layers
│ ├ 01-networks # manage VPC, subnets, common security groups. output vpc/subnets/security group id.
│ ├ 02-computing # manage computing resources into the vpc/subnets.
│ ├ 03-application # manage application-specific resources
├ modules # in-house terraform modules
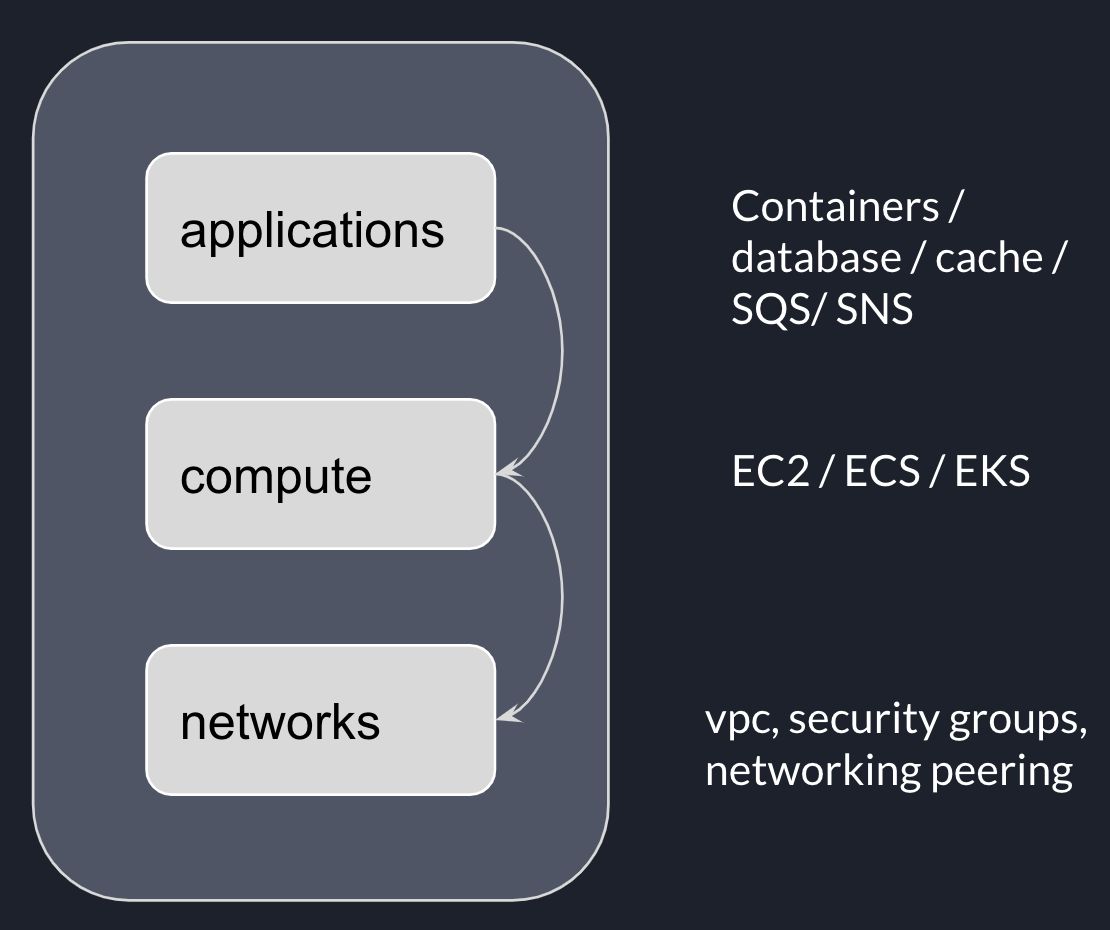
There are many benefits of adopting this approach, such as
- Enables independent provisioning of each component (when the component’s output doesn’t change)
- Fast deployment for the benefits of less state comparison.
Conclusion
We explored the problem layered infrastructure trying to solve; The benefits of this approach, and how to adapt it in your project.
This idea was inspired by Terraform Best Practices.