Tracking the Root Cause of a Topic Co-Partition Issue
Tracking the root cause of a topic co-partition issue
When joining streams in Kafka Stream application, one critical prerequisite is that topics need to be co-partitioned.
In this post, I’ll share my experience of tracking down an issue of topics not fulfilling co-partition guarantee, when using DefaultPartitioner and confluent’s KafkaAvroSerializer in topic key.
Background
- Service A producing events to topic A, with key
K. - Service B producing events to topic B, with the same key
K. - Service C joins events from both topics A and topic B and produce a calculated result to topic C, with the same key
K. - All topics have the same number of partitions
10. - These topics key schema registration strategy is TopicNameStrategy.
- key serializer is KafkaAvroSerializer.
- All three services use DefaultParitioner in the producer.
The Issue
Service A and B produces records with key k1 to corresponded topics, When service C create two KafkaStream from topic A and B, and join them together; it complains that no matching record for key k1.
Let’s revisit the definition of Copartition Requirements.
One additional item I would like to add to this requirements is:
For the same key, the record should be on the same partition across these co-partitioned topics.
Service C complains that it can not find a matching record for key k1 as it considers only records from the same partition on both topics, while in reality,k1 was sent to partition 2 of topic A but partition 0 of topic B.
Even the configuration of topic A and B, service A, B and C meet all the requirements defined above, why is that?
Uncover the root cause
The following diagram demonstrates how the partition number calculated.
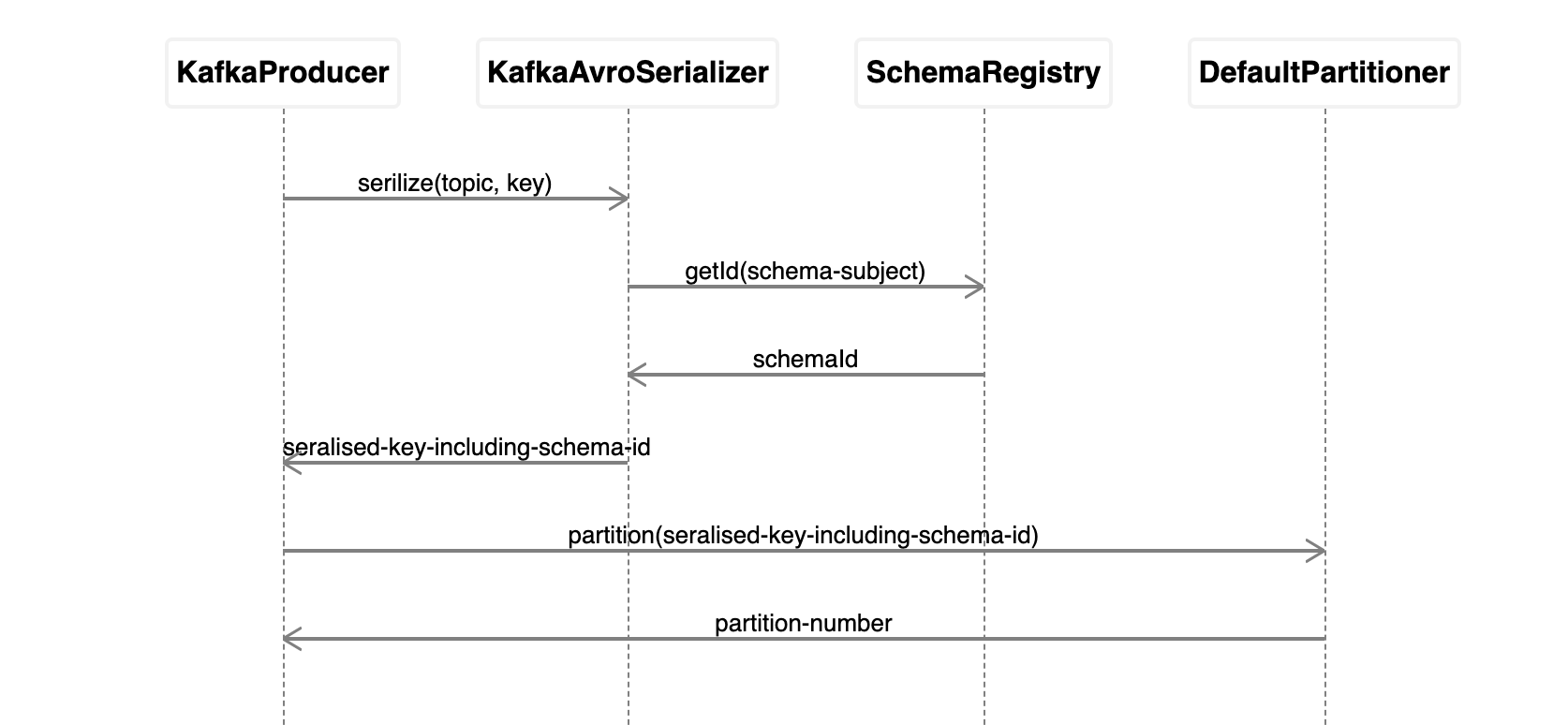
Firstly KafkaProducer delegate to KafkaAvroSerializer to serialize an Avro object to a byte array,
the serialized result includes schema id.
//org.apache.kafka.clients.producer.KafkaProducer#doSend
//In current context, keySerializer is an instance of KafkaAvroSerializer
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
Secondly, the keySerializer talk to schema registry to resvole the schema Id for topic key and append it to serialized bytes.
//io.confluent.kafka.serializers.AbstractKafkaAvroSerializer#serializeImpl
id = schemaRegistry.getId(subject, new AvroSchema(schema)); //as we're using TopicNameStrategy, the subject is "A-key" or "B-key"
ByteArrayOutputStream out = new ByteArrayOutputStream();
out.write(MAGIC_BYTE);
out.write(ByteBuffer.allocate(idSize).putInt(id).array());
Thirdly, KafkaProducer hand the serialzation result to DefaultPartitioner to calculate partition number.
//org.apache.kafka.clients.producer.KafkaProducer#partition
partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster;
Lastly, DefaultPartitioner calculate parition number from serialized key bytes.
// org.apache.kafka.clients.producer.internals.DefaultPartitioner#partition
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
Root Cause
-
Key schema registration strategy is
TopicNameStrategy, The same schema ofKis registered with topic A and topic B separately; hence different schema Id is generated for topic A topic B. -
When service A and service B serializing
k1, they append the different schema Id in the serialized bytes; Even though the Avro serialized value ofk1in two services are identical, the serialized key bytes are different. -
DefaultParitionercalculates partition from serialized bytes, and yields different partition number in two services.
Solution
There’re two ways to address this problem; both have pros and cons.
- Use other primitive type and Serde in topic key, e.g. StringSerializer, LongSerializer, etc.
The upside of this approach is co-partition is guaranteed as long as these requirements are met. The downside is losing the ability to evolve key schema. (who want to do this anyway?)
- Use a customized partitioner
The upside of this approach is the ability to evolve key schema. The downside is additional complexity to services.
Conclusion
Using DefaultPartitioner and KafkaAvroSerializer in the topic key will make the topic fail to meet co-partition requirements.
Caveats
RecordNameStrategy won’t help in this case, as when there’s a need to upgrade the key schema, new schema id will be generated, which in turn generate different serialized bytes and yield different partition number.
Even for the same key.