Rx Revisit
Rx revisit
TLDR;
本文是rx-java的后续,
将简要介绍Rx的起源,其多线程实现机制,另外会对其实现中的一个重要函数lift函数原理进行介绍。
Rx
Rx实际上是一种高级版本的Observer模式,把被观察者封装成Observable(可理解为一个异步地生产元素的集合),
然后通过 onNext, onError, onCompleted注册Observer在相应场景下需要执行的 回调。
值得一提的是,Rx为Observable提供了的filter,map/flatMap, merge, reduce等操作,使得对被观察者的操作就像同步集合那么便利。
起源
注: 此部分参考了这个slides
Netflix做为RxJava的主要贡献者,把Rx.Net移植到了JVM上,下面我们就通过一个架构演进来了解一下RxJava的起源。
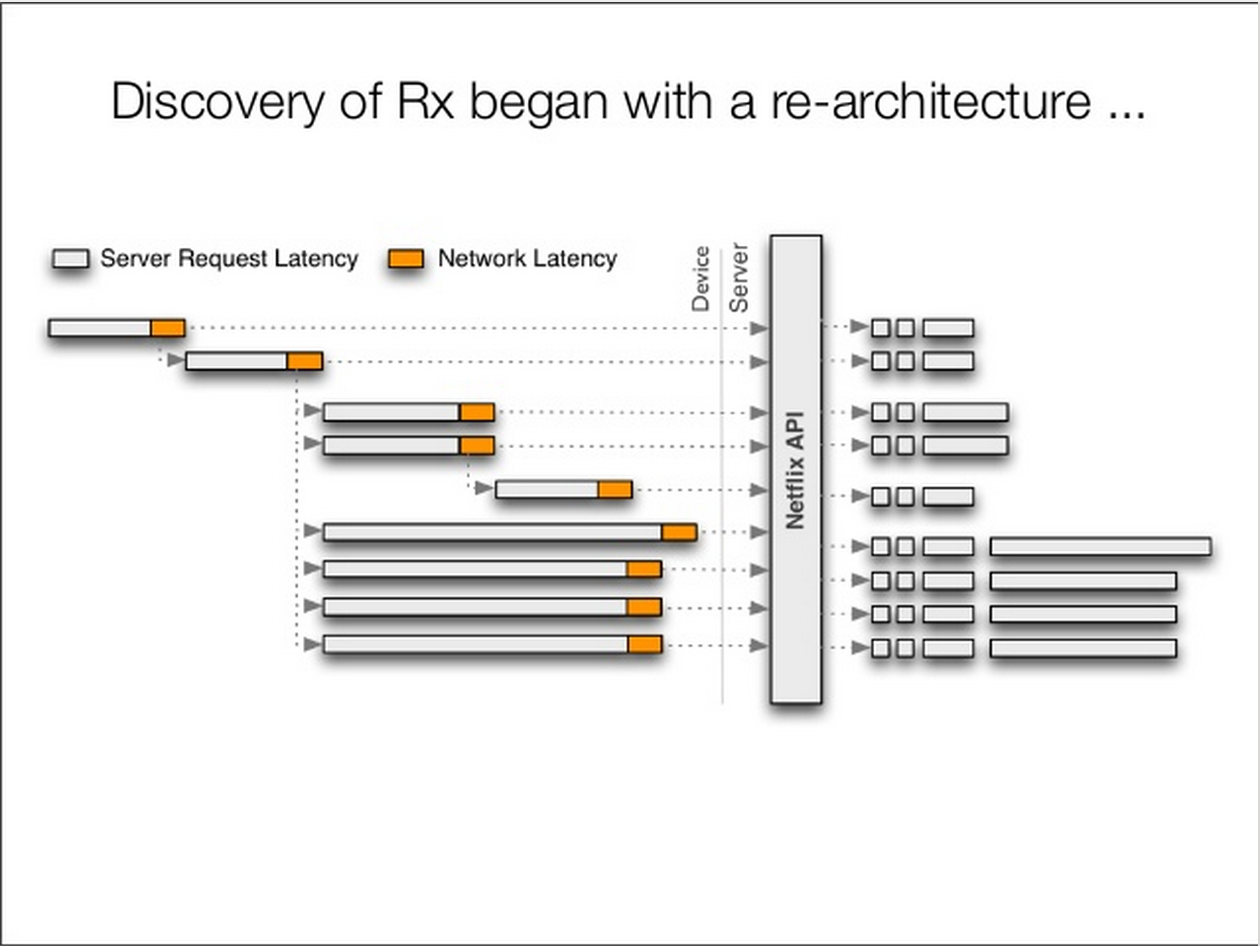
Netflix做为知名的流媒体提供商,坐拥3300万用户,其峰值下行流量可占北美地区互联网流量的33%,API请求量达到20亿次/天,面对众多的接入设备和巨量的API请求量, Netflix的工程师发现是时候重新架构他们的API了,之前他们的API架构如下:
为了减少API调用的延迟,工程师们决定转向粗粒度的API设计:
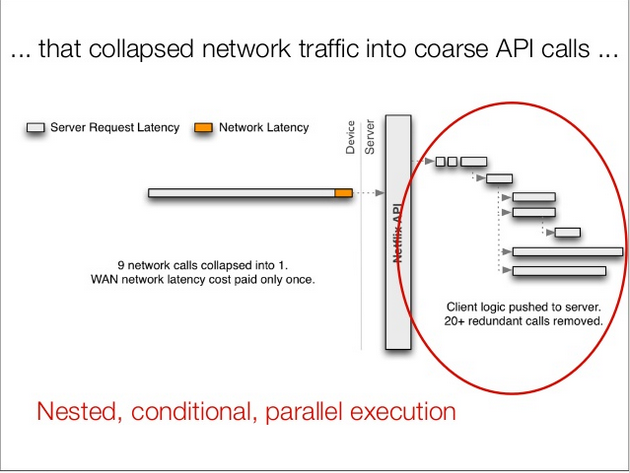
粗粒度API设计意味着业务逻辑向服务器端迁移,必将在服务器端出现并行执行,嵌套调用。
与此同时,我们希望API的提供者能够对外部隐藏其底层并发的实现,什么意思呢?
我们来看一个反面教材:
public Bookmark getBookmark(Long userId)如果某天,我们的程序员说,这个接口执行时间太长了,我不想阻塞调用此方法的线程,做为API提供者,你应该会立刻想到采用如下方案:
public Future<Bookmark> getBookmark(Long userId)把返回值类型修改为Future<Bookmark>,这样就不会阻塞API调用者的线程,同时在内部使用一个新的线程或者线程池执行业务逻辑。
又过了一段时间,我们的产品经理说,需求变了,我们希望能给一个用户关联多个Bookmark,你很开心地把接口修改成如下形式:
public Future<List<Bookmark>> getBookmark(Long userId)然后和你们对接的客户端程序员实在忍受不了三番五次的接口改动,提着刀过来找你了。
在被砍得奄奄一息之后,你终于问出了这个问题:
有没有一种数据结构能够表示一个或多个在未来可用的结果,并且仅在结果可用时把结果传递给客户程序,客户程序无需了解其内部的并发实现?
有!Observable来救场
我曾在上篇博客里提到Observable的定义,我们这里再回顾一下:
Observable用于表示一个可被消费的数据集合(data provider),它的消费者无需知道数据的产生机制同步的还是异步的,它会在数据可用,出错,以及数据流结束时通知它的消费者
实际上,Observable和Iterable是一组__对偶的(dual)__的概念,它们都被用来表示多个元素的集合,不同之处在于:
Observable中的元素可以是异步产生的,而Iterable中的所有元素在其被消费前必须可用。Observable是push- based,其可以在元素可用,出错,所有元素都被消费完成时通知他的消费者;而Iterable是pull-based,其消费者必须主动地轮询新元素,主动地捕获异常,主动地处理所有元素都被消费完成。
如果用Observable来改造上述API,那么我们的API就是下面这个样子:
public Observable<Bookmark> getBookmark(Long userId)那么无论是需要同步返回,异步返回,或者异步返回多个Bookmark,这个API都无需做任何变更, API内部可以:
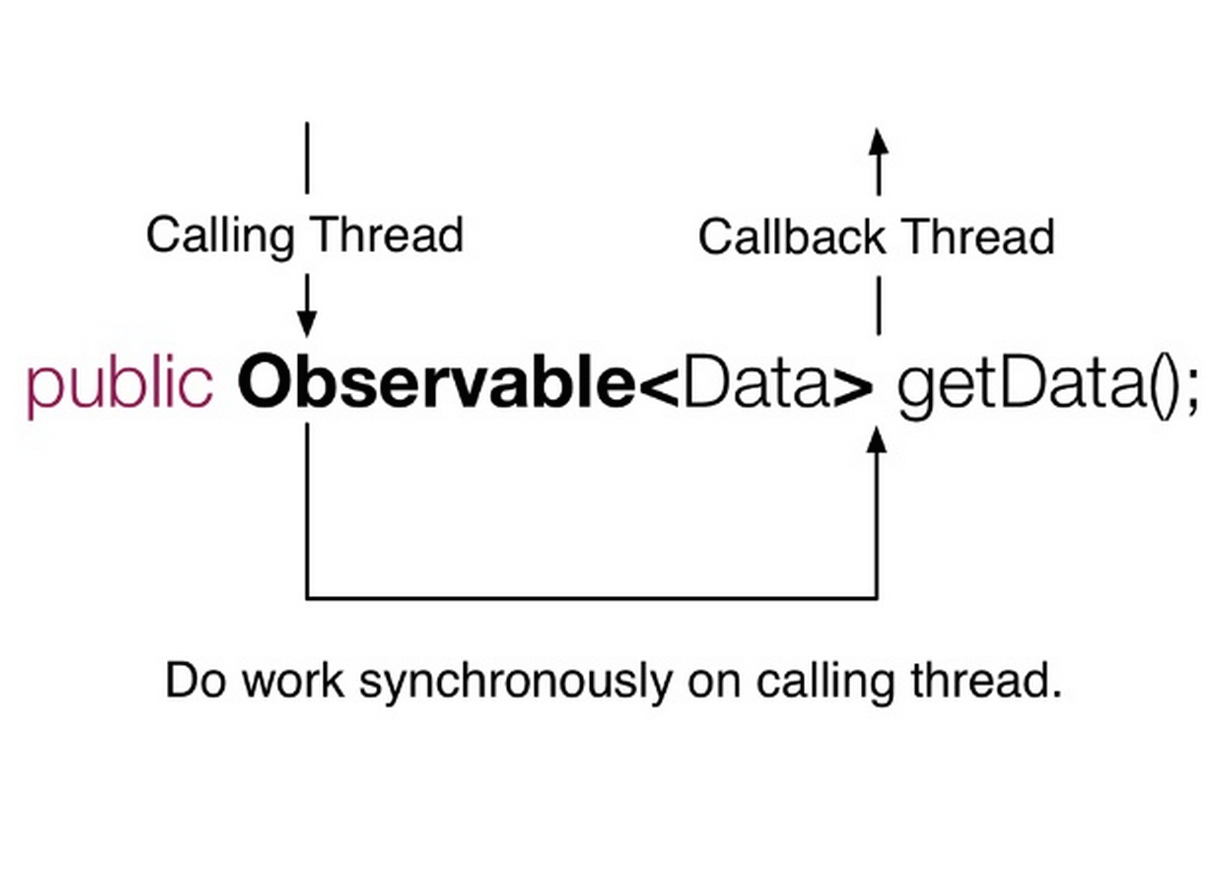
- 使用调用线程进行业务逻辑计算,在运算完成后通过
onNext将结果传递给客户端(原生的阻塞式调用)。
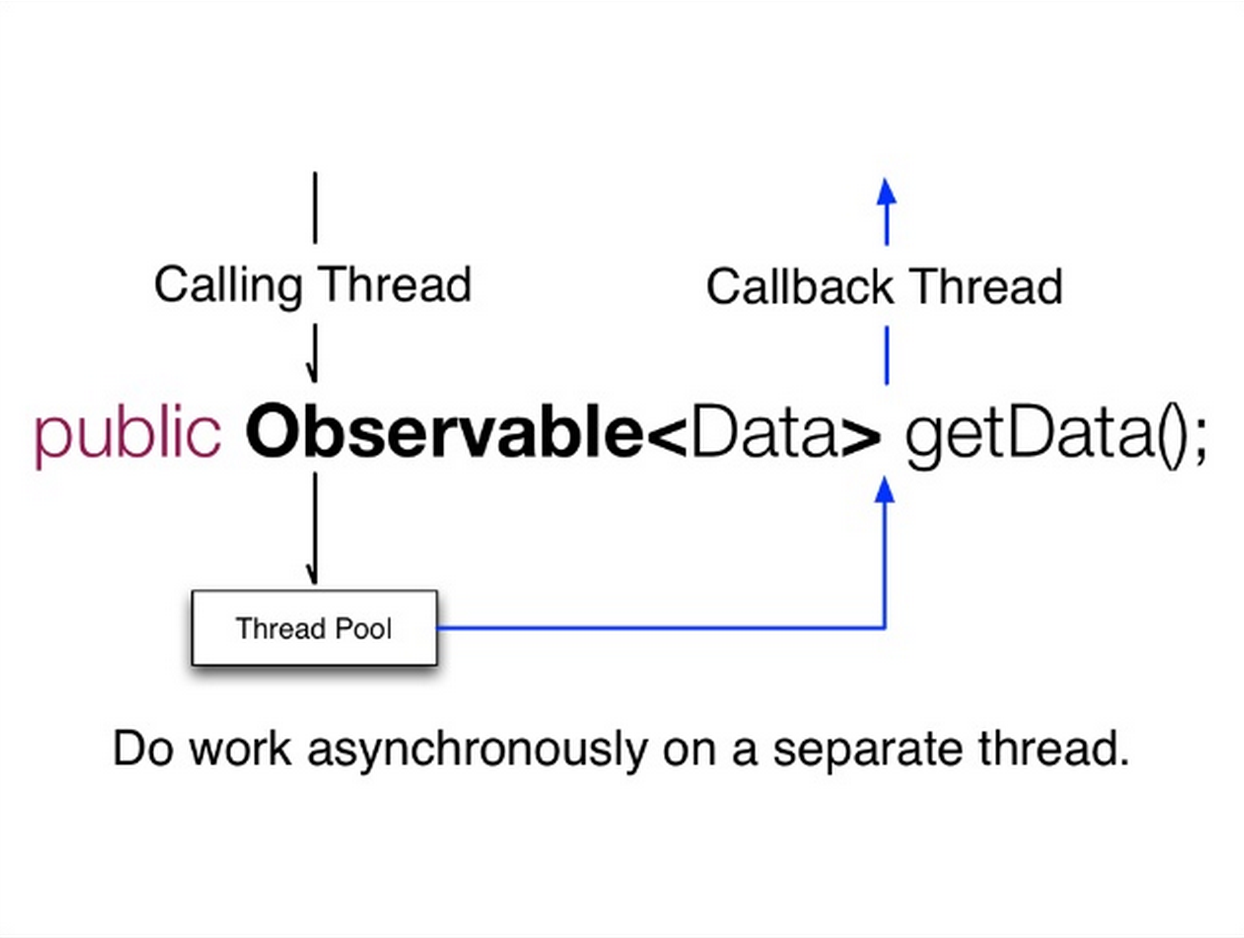
- 使用一个新线程,或者一个新的线程池进行业务逻辑计算,在运算完成后通过
onNext将结果传递给客户端(满足了异步返回的需求)。
- 使用多个新线程,或者一个新的线程池分别获取多个bookmark,在获得每个bookmark之后多次通过
onNext将结果传递给客户端(满足了异步返回多值的需求)。
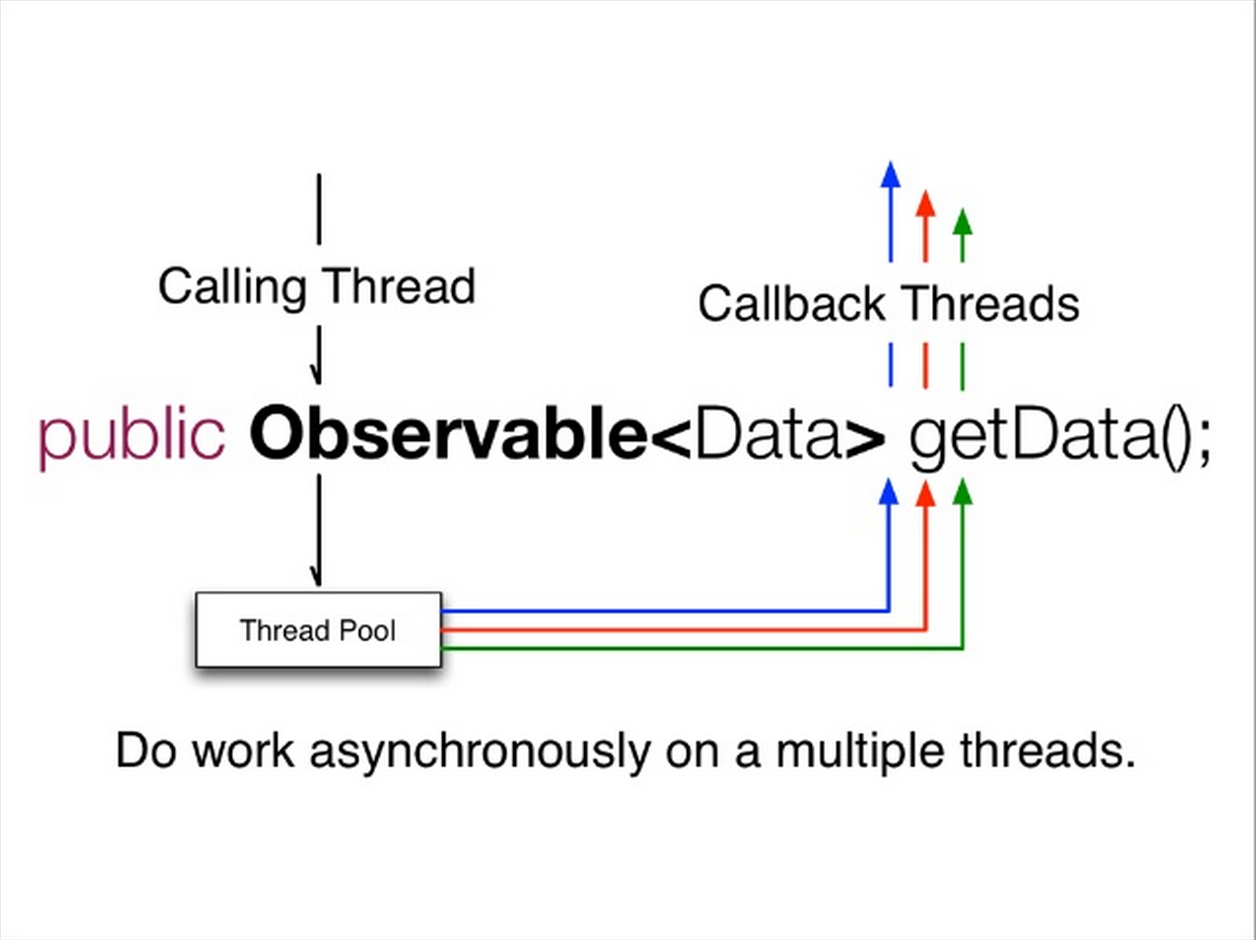
如此大的变化,客户无需做任何改动,这就是Observable高超的抽象能力带来的好处。 这就是Rx带来的巨大好处,也是Netflix把它移植到JVM上的最大动力。
原理
既然Observable这么强大,那么我们不禁会问:
- 为什么
Observable能够做到push-based? Observable是如何做到使用多种并发实现的?
对于第一个问题,Observable提供了subscribe方法供客户程序注册回调函数,之后Observable会自己进行运算并调用相应的回调函数,
这样看起来就像是Observable在向自己的客户程序push其运算结果。
对于第二个问题,Rx中有个非常重要的概念—— Scheduler,它是Rx提供的一种并发模型抽象,你可以在创建你的Observable时指定采用哪种并发模型, 下面我们来看下Scheduler是如何对并发模型进行抽象的。
Scheduler
Rx的默认行为是单线程的,它是一个free-threaded t1模型,意味着你可以自由选择一个线程来执行你指定的任务。
如果你创建Observable时没有引入scheduler,那么你注册的onNext, onError, onCompleted回调将被当前线程(即,创建Observable代码所在线程)上执行。
Scheduler提供一种机制,用于指定将会执行回调的线程。
Scheduler的多种实现:
-
EventLoopsScheduler
维护一组workers,当有新的任务加入
#schedule时,通过round-robin的方式选取一个worker,将任务分配给其执行Worker#scheduleActual -
CachedThreadScheduler
使用一个
ConcurrentLinkedQueue缓存创建出来的线程以备后续任务使用,创建出来的线程有一定的有效期,超过有效期的线程会被自动清除。 -
ExecutorScheduler
包装了一个
Executor的实例并,并基于它实现了Scheduler的接口。 注意,在这个实现里,thread-hopping(线程跳跃)问题是不可避免的,因为Scheduler并不知晓其包装的Executor的线程行为。 -
ImmediateScheduler
立即在当前线程上执行任务。
-
TrampolineScheduler
把任务分配给当前线程,但并不立即执行,任务会被放到一个队列中等待当前任务执行完毕。
Worker
回调的实际执行者,底层由java.util.concurrent.ExecutorService执行实际的任务,同时扮演了Subscription的角色。
总结
笔者在学习Coursea上学习Principal of Reactive Programming时,注意到Erik Miller曾打趣地说,不要自己尝试去实现Observable,使用现有的库就好了。 本着强大的好奇心,笔者还是试着阅读了Rx.java的源代码,才意识到这个模型是多么的精巧,它给多线程编程带来了革命性的体验。如果你对Rx.java有兴趣,强烈推荐阅读其源码。
Note: 这本应该重开一篇博客,然而,原谅笔者的懒惰吧
lift函数
在Observable的实现里,有个函数必须得提一下,lift。
Rx中巧妙提出一个Operator的这个函数类型,表述从一个Subscriber 到另一个 Subscriber的映射。
有大量对Observable的操作是通过定义Operator 并 lift 到Observable上实现的,如Observable#all, Observable#filter, Observable#finallyDo等等。
Observable#lift签名如下:
//inside Observable[T]
def lift[T, R](Operator[R, T]): Observable[R]lift函数简介
有一定函数式编程基础的人相信对lift这个名字都不会太陌生。
lift顾名思义,把一个对简单类型操作的函数提升(lift)到复杂类型/容器类型上去。
我们来看一个对lift的定义:
有个两个类型 A, B
和一个函数 f: A => B
和一个容器 M[_]
lift 就是把f转换成一个新的函数 M[A] => M[B]
那么lift的定义如下:
def lift[A, B, M[_]](f: A => B): M[A] => M[B]跟上面看到的Observable#lift唯一不同的地方在于,这个lift函数的返回值是一个函数,
不过再仔细观察一下,这个M[A] => M[B]应用到一个M[A]实例后的效果和上面的Observable#lift是一样的。
听起来比较抽象,其实只要我们把上面的符号逐个替换成我们所熟知的类型,这个函数一点都不陌生。 我们来逐步应用如下替换法则:
A: StringB: IntM: List[_]f: String => Int
因此,lift的类型签名如下:
(String => Int) => (List[String] => List[Int])
我们就暂且用 (s: String) => s.length做为我们的f吧,
假如有个字符串列表 xs: List[String],
那么 lift(f)(xs) 就会得到xs的中每个字符串的长度。
什么?
这不就是 xs.map(f)的结果吗?
是的,map函数就是一种常见的lift函数。
Observable#lift
我们再来看看lift在Observable中发挥了什么样的作用?
在开始之前大家需要记住这几个类型等式(:= 表示其左右两边的类型相等):
Observable[_] := Subscriber[_] => UnitOperator[T, R] := Subscriber[R] => Subscriber[T]
现在我们来做类型替换:
A: Subscriber[R]B: Subscriber[T]M: Observable[_] (即 Subscriber[_] => Unit)f: Subscriber[R] => Subscriber[T]
因此lift就是
(Subscriber[R] => Subscriber[T]) => (Subscriber[T] => Unit) => (Subscriber[R] => Unit)亦即
(Subscriber[R] => Subscriber[T]) => (Observable[T] => Observable[R])假如有个ts: Observable[T] 和一个函数f: Subscriber[R] => Subscriber[T],通过lift函数,我们就能得到一个类型为 Observable[R]的结果。
t1: 与free-threaded模型相对的是single-threaded apartment,意味着你必须通过一个指定的线程与系统交互。
Rx revisit
TLDR;
This post is a follow-up to my rx-java article. It briefly introduces the origins of Rx, its multi-threading implementation, and explains the important lift function used in its implementation.
Rx
Rx is essentially an advanced version of the Observer pattern. It wraps the subject being observed as an Observable (think of it as a collection that asynchronously produces elements), then registers callbacks for Observers via onNext, onError, and onCompleted for the appropriate scenarios.
Notably, Rx provides operations such as filter, map/flatMap, merge, and reduce on Observables, making it as convenient to work with as a synchronous collection.
Origins
Note: This section references these slides
Netflix, as a major contributor to RxJava, ported Rx.Net to the JVM. Let’s trace the origins of RxJava through an evolution of Netflix’s architecture.
Netflix, as a well-known streaming media provider with 33 million subscribers, with peak downstream traffic accounting for 33% of North American internet traffic and 2 billion API requests per day, found that it was time to rethink their API architecture. Their previous architecture looked like this:
To reduce API call latency, engineers decided to move toward a coarse-grained API design:
A coarse-grained API design means business logic migrates to the server side, which inevitably results in parallel execution and nested calls on the server.
At the same time, we want API providers to hide their underlying concurrency implementation from callers. What does that mean?
Let’s look at a counterexample:
public Bookmark getBookmark(Long userId)One day, a developer says: “This API takes too long — I don’t want to block the calling thread.” As the API provider, you’d naturally think of this solution:
public Future<Bookmark> getBookmark(Long userId)Changing the return type to Future<Bookmark> prevents blocking the caller’s thread, while internally a new thread or thread pool handles the logic.
Then one day, the product manager says: “Requirements changed — we want to support multiple Bookmarks per user.” Happily, you update the API:
public Future<List<Bookmark>> getBookmark(Long userId)At this point, the client-side developers who integrate with your API have had enough of the constant interface changes and are ready to come after you.
After nearly being done in, you finally ask:
Is there a data structure that can represent one or more results available in the future, delivering them to the caller only when ready, without the caller needing to know anything about the internal concurrency implementation?
Yes! Observable to the rescue
I mentioned the definition of Observable in my previous post. Let’s revisit it here:
Observable represents a consumable data collection (data provider). Consumers need not know whether data production is synchronous or asynchronous — it notifies consumers when data is available, when an error occurs, and when the data stream has ended.
In fact, Observable and Iterable are a pair of dual concepts — both represent collections of multiple elements, but they differ in key ways:
- Elements in an
Observablecan be produced asynchronously, whereas all elements in anIterablemust be available before they can be consumed. Observableis push-based: it notifies consumers when elements are available, when an error occurs, and when all elements have been consumed.Iterableis pull-based: consumers must actively poll for new elements, catch exceptions themselves, and handle completion themselves.
If we redesign the API above using Observable, it would look like this:
public Observable<Bookmark> getBookmark(Long userId)Now regardless of whether synchronous return, asynchronous return, or asynchronous return of multiple Bookmarks is needed, the API signature never changes. Internally, the API can:
- Use the calling thread for computation, then deliver the result via
onNextwhen done (native blocking call).
- Use a new thread or thread pool for computation, then deliver the result via
onNextwhen done (satisfies async return requirement).
- Use multiple threads or a thread pool to fetch multiple bookmarks in parallel, calling
onNextfor each result (satisfies async multi-value return requirement).
Despite such significant internal changes, clients need not change anything. That’s the power of Observable’s elegant abstraction. This is the enormous benefit Rx brings, and the primary motivation for Netflix to port it to the JVM.
How It Works
Given how powerful Observable is, we naturally ask:
- Why can
Observablebe push-based? - How does
Observablesupport multiple concurrency implementations?
For the first question: Observable provides a subscribe method for clients to register callback functions. Observable then performs its computation and invokes the appropriate callbacks, making it appear as though the Observable is pushing results to its clients.
For the second question: Rx has an important concept called Scheduler — an abstraction over concurrency models. You can specify which concurrency model to use when creating an Observable. Let’s see how Scheduler abstracts over concurrency.
Scheduler
Rx’s default behavior is single-threaded. It is a free-threaded t1 model, meaning you can freely choose which thread executes a given task.
If no scheduler is introduced when creating an Observable, the registered onNext, onError, and onCompleted callbacks will execute on the current thread (i.e., the thread where the Observable was created).
The Scheduler provides a mechanism to specify on which thread callbacks will execute.
Scheduler Implementations:
-
EventLoopsScheduler
Maintains a pool of workers. When a new task is submitted via
#schedule, a worker is selected via round-robin and the task is dispatched viaWorker#scheduleActual. -
CachedThreadScheduler
Uses a
ConcurrentLinkedQueueto cache created threads for later reuse. Created threads have a time-to-live and are automatically removed when they expire. -
ExecutorScheduler
Wraps an
Executorinstance and implements theSchedulerinterface on top of it. Note that in this implementation,thread-hoppingis unavoidable because the Scheduler has no knowledge of the thread behavior of the underlyingExecutor. -
ImmediateScheduler
Executes tasks immediately on the current thread.
-
TrampolineScheduler
Assigns tasks to the current thread, but does not execute them immediately. Tasks are queued and executed after the current task completes.
Worker
The actual executor of callbacks. Internally backed by java.util.concurrent.ExecutorService for task execution, and also plays the role of a Subscription.
Summary
While studying the Principles of Reactive Programming on Coursera, I noticed that Erik Meijer jokingly said: “Don’t try to implement Observable yourself — just use the existing library.” Out of curiosity, I went ahead and read through the RxJava source code anyway, and came to appreciate just how elegant this model is. It brings a revolutionary experience to multi-threaded programming. If you’re interested in Rx.java, I strongly recommend reading through its source code.
Note: This should have been a separate blog post, but please forgive my laziness.
The lift Function
There is one function in Observable’s implementation that deserves special mention: lift.
Rx cleverly introduces a function type called Operator, which represents a mapping from one Subscriber to another Subscriber.
Many operations on Observable are implemented by defining an Operator and lifting it onto an Observable — for example, Observable#all, Observable#filter, Observable#finallyDo, and many others.
The signature of Observable#lift is as follows:
//inside Observable[T]
def lift[T, R](Operator[R, T]): Observable[R]Introduction to the lift Function
Anyone with a functional programming background will likely be familiar with the name lift.
As the name suggests, it takes a function that operates on a simple type and lifts it to work on a complex/container type.
Let’s look at a definition of lift:
Given two types A and B
and a function f: A => B
and a container M[_]
lift transforms f into a new function M[A] => M[B]
Thus, lift is defined as:
def lift[A, B, M[_]](f: A => B): M[A] => M[B]The only difference from the Observable#lift we saw above is that this lift returns a function.
But on closer inspection, applying M[A] => M[B] to an M[A] instance produces the same effect as Observable#lift.
This sounds abstract, but once we substitute the symbols with familiar types, it becomes quite recognizable. Let’s apply the following substitutions step by step:
A: StringB: IntM: List[_]f: String => Int
Therefore, the type signature of lift becomes:
(String => Int) => (List[String] => List[Int])
Let’s use (s: String) => s.length as our f.
Given a list of strings xs: List[String],
lift(f)(xs) would give us the length of each string in xs.
Wait —
Isn’t that just xs.map(f)?
Yes! The map function is a common instance of lift.
Observable#lift
Now let’s see what role lift plays within Observable.
Before we begin, keep these type equalities in mind (:= means the two sides are equivalent types):
Observable[_] := Subscriber[_] => UnitOperator[T, R] := Subscriber[R] => Subscriber[T]
Now let’s apply the type substitutions:
A: Subscriber[R]B: Subscriber[T]M: Observable[_] (i.e. Subscriber[_] => Unit)f: Subscriber[R] => Subscriber[T]
Therefore, lift becomes:
(Subscriber[R] => Subscriber[T]) => (Subscriber[T] => Unit) => (Subscriber[R] => Unit)Which is equivalent to:
(Subscriber[R] => Subscriber[T]) => (Observable[T] => Observable[R])Given a ts: Observable[T] and a function f: Subscriber[R] => Subscriber[T], by applying lift, we obtain a result of type Observable[R].
t1: The opposite of the free-threaded model is the single-threaded apartment model, which means you must interact with the system through a designated thread.